Bukan rahasia lagi kalau scanner A3 harga mahal hingga puluhan juta. Sementara untuk membeli scanner A3, dokumen A3 yang harus diproses jumlahnya cuma sedikit. Untuk mengatasi hal ini penulis menyarankan penggunaan scanner yang memiliki kemampuan memproses dengan Carrier Sheet atau Folio Scanning.
Carrier Sheet adalah suatu map plastik khusus yang didesain untuk memproses lembar A3 dengan scanner A4. Bagaimana cara bekerjanya ? Pertama kita harus melipat kertas A3 sehingga berbentuk A4 kemudian dimasukkan ke dalam carrier sheet. Kemudian kita mengatur setting scanner duplex (melakukan scanning dua sisi sekaligus) dan option mode : carrier sheet. Maka kemudian lembar dalam plastik carrier sheet diproses oleh scanner dan menghasilkan image berukuran A3 (A4 x 2 muka digabungkan otomatis). Scanner yang dilengkapi kemampuan memproses carrier sheet adalah Fujitsu Scansnap S510 dan Fujitsu Fi 6010 N.
Folio Scanning adalah fitur scanner untuk memproses lembar A3 dengan scanner A4 cukup dengan melipat kertas A3 menjadi A4 serta melakukan pemindaian dan langsung menghasilkan image berukuran A3, tanpa menggunakan carrier sheet. Cara melakukan scanning dengan fitur ini mudah sekali, tinggal melakukan setting folio scanning dan meletakkan kertas A3 yang telah dilipat ke dalam tray ADF dan hasilnya adalah image berukuran A3. Folio scanning adalah fitur yang miliki scanner Canon, salah satunya DR 3080 CII.
Kelemahan sistem ini adalah kualitas image sering terdistorsi apabila kita tidak melipat lembar A3 tersebut dengan benar. Namun untuk kualitas yang acceptable solusi ini memang akan banyak menghemat investasi.

Kamis, 23 April 2009
Automatic Page Detection pada Scanner ADF (Automatic Document Feeder)
Fitur penting untuk memproses lembar dokumen berbagai ukuran secara otomatis
Dalam melakukan scanning dokumen, seringkali kita bertemu dengan berbagai ukuran kertas yang harus kita pindai sebagai satu bundel file atau satu folder file. Teori idealnya adalah kita harus melakukan pemindaian pada satu jenis ukuran dokumen dengan suatu setting, kemudian dokumen lain dengan setting yang berbeda lagi.
Namun kenyataannya suatu dokumen biasanya harus mengikuti urutan tertentu meskipun ukuran dari setiap dokumennya berbeda-beda. Misalnya pada aplikasi lamaran pekerjaan yang mensyaratkan urutan surat lamaran pekerjaan, CV, surat keterangan sehat dari dokter, fotocopy KTP , Ijazah dan lain sebagainya yang kisaran ukurannya mulai A6 hingga legal bahkan A3. Bagaimana jika kita mendapatkan pekerjaan untuk melakukan scanning 2 juta lembar dokumen pegawai misalnya, apakah setiap ukuran kertas kita melakukan setting sebelum pemindaian?
Jangan terlalu kuatir. Di dalam scanner Automatic Document Feeder (ADF) kebanyakan telah dilengkapi oleh fitur Automatic Page Detection dengan berbagai nama alias antara lain Autopage Detection, Scanners Maximum, dan Autosize Documents. Dengan fitur ini kita cukup melakukan setting kertas terbesar saja, kemudian hidupkan opsi automatic page detection dan scanner otomatis melakukan pemindaian image sesuai dengan ukuran masing-masing kertas. Dengan bantuan ini maka pekerjaan pemindaian dapat menjadi lebih cepat karena hanya dengan satu setting saja, satu bundel dokumen berbagai ukuran dapat dipindai dengan cepat dan mudah.
Bagaimanakah batas dari Automatic Page Detection ini ? Hal ini sangat tergantung dari spesifikasi scannernya. Untuk scanner Fujitsu dan Avision misalnya untuk scanner A4 akan dibatasi hingga panjang 35 cm atau 14 inch, untuk melakukan scanning lebih panjang dari itu, setting scanner harus didefinisikan sebagai long page scanning (hingga sekitar 3 meter kalau tidak dipaksakan, penulis pernah memaksakan hingga 6 meter) yang harus benar-benar sesuai dengan ukuran dokumen (perlu diukur pakai penggaris). Untuk scanner Kodak memang luar biasa mudah, kita tidak perlu mendefinisikan apa-apa setelah memilih Automatic Page Detection, scanner ini dapat memproses document sepanjang maksimum 3 meter.
Keterbatasan kualitas cropping dari sebuah scanner akan ditentukan oleh kualitas dokumennya. Apabila kita melakukan scanning dokumen yang terlipat maka ujung lipatan akan berwarna hitam legam kecuali kita melakukan setting white background pada scanner.
Anda menjalani pekerjaan scanning dengan berbagai ukuran dokumen ? Carilah scanner ADF yang memiliki fitur Automatic Page Detection.
Dalam melakukan scanning dokumen, seringkali kita bertemu dengan berbagai ukuran kertas yang harus kita pindai sebagai satu bundel file atau satu folder file. Teori idealnya adalah kita harus melakukan pemindaian pada satu jenis ukuran dokumen dengan suatu setting, kemudian dokumen lain dengan setting yang berbeda lagi.
Namun kenyataannya suatu dokumen biasanya harus mengikuti urutan tertentu meskipun ukuran dari setiap dokumennya berbeda-beda. Misalnya pada aplikasi lamaran pekerjaan yang mensyaratkan urutan surat lamaran pekerjaan, CV, surat keterangan sehat dari dokter, fotocopy KTP , Ijazah dan lain sebagainya yang kisaran ukurannya mulai A6 hingga legal bahkan A3. Bagaimana jika kita mendapatkan pekerjaan untuk melakukan scanning 2 juta lembar dokumen pegawai misalnya, apakah setiap ukuran kertas kita melakukan setting sebelum pemindaian?
Jangan terlalu kuatir. Di dalam scanner Automatic Document Feeder (ADF) kebanyakan telah dilengkapi oleh fitur Automatic Page Detection dengan berbagai nama alias antara lain Autopage Detection, Scanners Maximum, dan Autosize Documents. Dengan fitur ini kita cukup melakukan setting kertas terbesar saja, kemudian hidupkan opsi automatic page detection dan scanner otomatis melakukan pemindaian image sesuai dengan ukuran masing-masing kertas. Dengan bantuan ini maka pekerjaan pemindaian dapat menjadi lebih cepat karena hanya dengan satu setting saja, satu bundel dokumen berbagai ukuran dapat dipindai dengan cepat dan mudah.
Bagaimanakah batas dari Automatic Page Detection ini ? Hal ini sangat tergantung dari spesifikasi scannernya. Untuk scanner Fujitsu dan Avision misalnya untuk scanner A4 akan dibatasi hingga panjang 35 cm atau 14 inch, untuk melakukan scanning lebih panjang dari itu, setting scanner harus didefinisikan sebagai long page scanning (hingga sekitar 3 meter kalau tidak dipaksakan, penulis pernah memaksakan hingga 6 meter) yang harus benar-benar sesuai dengan ukuran dokumen (perlu diukur pakai penggaris). Untuk scanner Kodak memang luar biasa mudah, kita tidak perlu mendefinisikan apa-apa setelah memilih Automatic Page Detection, scanner ini dapat memproses document sepanjang maksimum 3 meter.
Keterbatasan kualitas cropping dari sebuah scanner akan ditentukan oleh kualitas dokumennya. Apabila kita melakukan scanning dokumen yang terlipat maka ujung lipatan akan berwarna hitam legam kecuali kita melakukan setting white background pada scanner.
Anda menjalani pekerjaan scanning dengan berbagai ukuran dokumen ? Carilah scanner ADF yang memiliki fitur Automatic Page Detection.
Debat OMR VS ICR pada Data Entry Tabulasi Pemilu 2009
Sebenarnya lebih baik ICR atau OMR ? Sepertinya topik ini mengemuka setelah pasca pemilu sistem tabulasi nasional tidak mencapai target yang diinginkan. Berikut adalah beberapa kutipan dari http://indonesiafile.com/content/view/1096/62/ :
Saking alotnya perdebatan itu, tim teknologi informasi KPU terbelah menjadi dua kubu. Aziz lebih memilih menggunakan ICR karena cocok dengan kondisi di lapangan. ICR lebih unggul dalam hal kecepatan perhitungan suara dan mudah dilakukan petugas. Hanya saja, Aziz berterus terang, memang ada yang meragukan kemampuan ICR untuk mendeteksi karakter angka tertentu. Angka seperti 1 dan 7, 3 dan 8, 6 dan 0 dalam tulisan tangan kadang-kadang memang hampir mirip. Tapi Aziz yakin, masalah itu telah teratasi. ''Sampai sejelek apa pun tulisan, karakternya masih bisa diidentifikasi,'' ujar Aziz.
Di sisi berlawanan, ada kelompok lain yang lebih memilih menggunakan teknologi optical mark recognition (OMR). Prinsipnya, OMR juga menjalankan fungsi pemindaian. Hanya saja, tak seperti ICR yang berusaha memindai tulisan tangan, OMR memindai data yang telah diberi tanda pada karakter abjad atau angka tertentu. ''Dengan cara ini, tingkat validitas dan akurasi data jelas lebih terjamin,'' kata Bambang Edi Leksono, pendukung metode OMR.
Penulis memandang bahwa dua teknologi tersebut sama-sama dapat berpeluang untuk sukses dijalankan pada tabulasi nasional Pemilu 2009,.Penulis melihat kedua pendapat di atas “benar” kecuali pada kata-kata “Sampai sejelek apa pun tulisan, karakternya masih bisa teridentifikasi” karena sampai sekarang ICR tercanggih pun belum pernah diimplementasikan untuk membaca resep obat dari seorang dokter disebuah apotik . (Itupun penulis masih ragu apakah kata-kata itu salah kutip atau memang demikian adanya, penulis tidak ingin berpolemik pada masalah tersebut).
Dari pengalaman penulis menjalankan ICR maupun OMR, mutlak diperlukan persiapan pelaksanaan yang cermat dan pendekatan yang berbeda pada masing-masing teknologi. Ibarat penulis berada di Klaten (kota kelahiran penulis yang terletak di antara Yogyakarta dan Solo/Surakarta) hendak terbang ke Jakarta, maka penulis harus memilih bandara Yogya Adi Sucipto atau Solo Adi Sumarmo. Untuk ke Yogya penulis harus menempuh jalan ke Gondang-Prambanan-Kalasan -Yogya sedangkan ke Solo penulis harus menempuh jalan ke Delanggu-Kartasura-Solo. Demikian pula pada kedua teknologi ini , keduanya membutuhkan pendekatan berbeda dalam mencapai tujuannya.
Optical Mark Recognition
OMR mengandalkan persentasi warna hitam (dari isian pensil/pena/spidol) pada suatu area tertentu yang akan dibaca sebagai data tertentu. Jadi seperti yang kita lihat pada lembar ujian UAN / UASBN / Rekrutmen berbentuk multiple choice, apabila kita mengarsir atau memberi tanda silang pada pilihan jawaban “A” maka aplikasi OMR akan membacanya sebagai “A”.
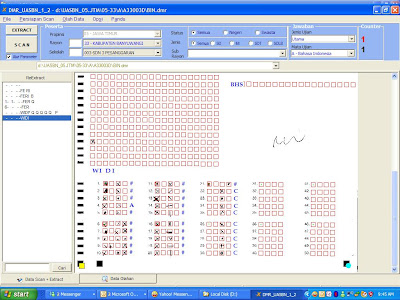
Mengapa penulis katanya produk OMR luar negeri tidak akan menang melawan produk OMR dalam negeri di Indonesia ? Karena persiapan pelaksanaan OMR di Indonesia biasanya memang lain daripada yang lain: Salah cetak formulir baik : salah ukuran, salah warna, salah potong hampir selalu terjadi di Indonesia, sehingga produsen OMR di dalam negeri pada awalnya bersusah payah melakukan re-engineering mengatasi hal ini. Belum lagi masalah salah pengisian nomor peserta, anulir nilai soal, isian pensil tipis-tipis, sosialisasi pengisian yang biasanya kurang baik atau mungkin ada satu-dua orang yang benar-benar tidak mengerti cara mengisinya biarpun disosialisasi berkali-kali.Apabila lembar ujian habis ? Mereka akan melakukan fotocopy lembar jawaban sebagai pengganti. Sederhana sekali.
Pada persiapan lembar ujian di luar negeri, penulis mengacu pada negeri tetangga Singapura, mereka mencetak dengan mesin cetak continuous form dengan presisi tinggi, menggunakan color drop out ink, yang mahalnya ampun-ampunan.Tidak menggunakan fotocopy. Aplikasi luar negeri di desain pada kondisi ideal seperti ini, makanya beberapa merk software OMR luar negeri berguguran di negeri ini karena tidak sanggup mengatasi lingkungan yang kurang terantisipasi oleh mereka. Berbanggalah saudara-saudara bahwa OMR buatan dalam negeri jauh lebih bandel…. karena memang lingkungan kita benar-benar bandel. (Ini diakui oleh seorang direktur ICR dari mancanegara dan rekan-rekan distributor scanner se Asia sewaktu penulis memperagakan salah satu software OMR dari Indonesia dengan segala kendala yang terjadi. Saat ini software ini digunakan di 3 negara Malaysia, Korea Selatan, dan Arab Saudi).
Bagaimana agar OMR sukses dalam implementasinya ?
1. Desain formulir OMR yang minim resiko. (maksudnya resiko salah warna, salah cetak, bulatan jawaban cukup jaraknya antara satu pilihan dengan pilhan lain, dan bulatan pilihan cukup besar agar tidak menyebrang ke pilihan tetangga ketika mengisi, gunakan mode dua warna cetak antara anchor (hitam) dan objek yang diisi (merah, biru, hijau – scanner mampu mendropout warna ini).
2. Sosialisasikan cara mengisi Lembar OMR dengan baik, berupa petunjuk pengisian maupun diperagakan cara pengisiannya sebagai contoh.
3. Lembar jangan sampai kotor, robek atau terlipat pada saat pengumpulan dan jangan sekali-kali distaples.
4. Kecepatan scanner sangat mempengaruhi proses OMR karena aplikasinya cenderung membaca lebih cepat daripada kecepatan scanner.
Bagaimana Kelemahan dari OMR ?
1. Keengganan Responden mengisi pada isian yang cukup banyak pada satu form.
Untuk mengisi nama lengkap, alamat, nama kota, nama propinsi dan deskripsi panjang memang tidak cocok menggunakan OMR, karena dapat membuat respondennya frustasi. Pada ujian sangat cocok untuk menggunakan OMR.
Mengisi lembar OMR pun membutuhkan waktu yang lebih lama.
2. Data yang dapat diperoleh dari suatu formulir OMR terbatas jumlahnya. Sehingga untuk data yang banyak diperlukan lembar yang banyak pula. Sehingga untuk keperluan ini scannernya perlu lebih banyak atau kapasitasnya lebih besar.
Bagaimana Keunggulan dari OMR?
1. Waktu Proses yang cepat dan akurasi yang sangat tinggi
Karena logika aplikasi yang hanya mengecek “hitam” atau “putih” pada area tertentu, maka prosesnya cenderung cepat dan akurat. Akurat disini artinya bahwa isian yang diisi oleh responden akan diterjemahkan secara benar. (artinya kalau respondennya salah isi, bukan dalam lingkup hitungan akurasi)
2. Operator scanner lebih nyaman dan lebih cepat dalam bekerja karena sangat minim verifikasi
Pengalaman penulis untuk memproses 115,000 peserta ujian psikotes hanya membutuhkan waktu 4 jam dengan scanner kecepatan 100 ppm sebanyak 2 unit dengan 2 operator dan 2 pembantu operator yang mengurus kertasnya (masih ditambah dua orang lagi yang sibuk membelikan makanan dan membuatkan kopi dan teh).
3. Target penyelesaian pekerjaan dapat terukur dengan baik
Pada proyek OMR, penulis dapat menentukan kapan pekerjaan diselesaikan dengan perkiraan yang tidak rumit. Bila ingin selesai 4 jam maka scanner yang dibutuhkan pada kecepatan sekian adalah sekian banyak ditambah beberapa operator.
Bagaimana Risiko yang membuat OMR gagal atau terganggu (berdasarkan jumlah keluhan pada organisasi penulis)
1. Lembar yang tidak didesain dari awal dan mutu percetakan Lembar OMR yang keterlaluan asal-asalannya (35% dari masalah yang ada)
2. Listrik Mati (3,5% dari masalah yang ada)
3. Scanner macet atau tidak berfungsi atau gagal install (malah tidak install driver) (28% dari masalah yang ada)
4. Operator yang tidak terampil, gampang ngambek , dan tidak datang tepat waktu atau malah bolos ( 1 % dari masalah yang ada)
5. Virus komputer (2,8 % dari masalah yang ada)
6. Salah memilih template pembacaan OMR (28% dari masalah yang ada)
7. Lupa atau kehilangan dongle lisensi OMR sehingga tidak bisa berjalan aplikasinya.(0,5 % dari masalah yang ada)
Inti dari Optical Mark Recognition adalah susah diawal (mengisi formulir nya) tetapi tidak repot di akhir (operator yang memproses).Optical Mark Recognition juga memiliki risiko kegagalan yang rendah apabila cara pengisiannya tersosialisasikan dengan baik.
Intelligent Character Recognition (ICR)
Intelligent Character Recognition adalah teknologi mengenali tulisan tangan manusia yang serupa mungkin dengan huruf cetak (hand printing) dari sebuah image dan diterjemahkan menjadi data. Ini adalah definisi bagi penulis secara sederhana.
Secara awam , aplikasi ini menerjemahkan suatu image , setelah melalui pemisahan huruf demi huruf (separasi), menjadi suatu teks dalam format digital. Image ini dihasilkan dari lembar ICR yang discan menjadi image atau citra digital.

Gambar 2. Implementasi Teknologi ICR di sebuah lembar biodata pada satu organisasi pemerintah
Bagaimana agar ICR sukses dalam implementasinya ?
1. Desain Formulir ICR yang rendah risiko (Membuat kotak huruf isian cukup besar, kotak huruf isian dapat dihilangkan pada saat scanning sehingga tidak mengganggu pembacaan ICR, Cetakan yang stabil, dan petunjuk pengisian yang jelas).
2. Kualitas cetakan formulir yang bermutu tinggi.
3. Kualitas image yang sangat jelas menjadi tolak ukur penting bagi proses ICR, teknologi ini menganalisa pattern atau bentuk citra mana yang sesuai dengan huruf atau angka mana, berbeda dengan OMR yang hanya mengukur hitam atau putih. Kualitas image didapatkan dari kualitas image scanner dan setting yang tepat sewaktu scanning.
4. Sosialisasi pengisian formulir ICR. Perlu diingatkan pada responden bahwa ICR memiliki keterbatasan dalam membaca tulisan mereka, sehingga kepatuhan mereka pada petunjuk pengisian akan menjadi kunci sukses implementasi.
5. Kecakapan operator ICR mulai dari ketrampilan mengoperasikan scanner pada kondisi kertas yang berbeda , mengoperasikan ICR , melakukan verifikasi dan validasi data.
6. Jumlah verifikator untuk implementasi harus banyak untuk mencapai target penyelesaian yang cepat, sehingga disini jumlah orang yang melakukan verifikasi menjadi kunci utama kecepatan ICR. Jadi kalau OMR perlu scanner cepat, ICR perlu komputer untuk verifikasi yang banyak, pada pengolahan skala besar. Pengalaman penulis untuk mencapai hasil 2000 lembar aplikasi kartu kredit (35-80 field) per hari dibutuhkan 1 operator scanner dan 8 orang verifikator dengan akurasi mendekati 98%.
7. Mekanisme verifikasi menjadi penting untuk mempercepat proses bagi aplikasi ICR, sehingga perlu dibuatkan interface yang memudahkan melakukan verifikasi.
8. Perlu kontrol kualitas akhir pada hasil untuk mencapai 100% Acccuracy.
9. Target waktu penyelesaian sukar diukur terutama pada awal proses, namun mulai biasanya mulai dapat diukur setelah 2-3 hari implementasi tergantung kerumitan formulir dan kemampuan operator.
Bagaimana Kelemahan dari ICR ?
1. Faktor akurasi awal tergantung dari berbagai variabel antara lain bentuk tulisan, pemilihan bentuk formulir, image yang dihasilkan oleh scanner yang harus menunjang ketajaman dan keutuhan bentuk pattern dari huruf atau angka. Faktor akurasi berikutnya sangat tergantung dari sikap mental operator yang teliti dan telaten dalam menjalankan proses ICR. Disini prosesnya tidak bisa terlalu dipaksakan untuk cepat untuk mencapai akurasi tinggi.
2. Operator yang berfungsi sebagai verifikator dan validator (apalagi yang biasa mengoperasikan OMR) akan cepat stress dan malas apabila hasil yang harus diverifikasi sangat banyak. Pelatihan intensif yang mencakup pengendalian image hasil scanner, pengoperasian ICR dan Verifikasi harus dilakukan dengan praktek yang cukup.
3. Perlu banyak orang untuk mengoperasikan komputer yang membantu proses verifikasi pada ICR.
4. Kadang diperlukan re-tune in data pada saat implementasi. Mengapa demikian? Berbeda dengan proses OMR pada field kode kota dalam 3 angka misalnya responden dipaksa mengarsir pada angka 0-9, sedangkan pada ICR disediakan kotak kosong sebanyak 3 buah yang diisi angka 0-9, namun pada banyak kasus sering diisi dengan kata “JKT”. Pada kasus ini template ICR harus dimodifikasi untuk memenuhi dua kriteria yang ada, mengapa begitu ? Karena yang salah dapat mencapai 30-40% dari responden, mengapa begitu ? Kembali ke topik awal tadi bahwa : “sosialisasi pengisian yang biasanya kurang baik atau mungkin ada satu-dua orang yang benar-benar tidak mengerti cara mengisinya biarpun disosialisasi berkali-kali”.
Keunggulan ICR
1. Mengisi formulir ICR itu mudah dibanding formulir OMR
2. Jumlah data yang termuat dalam satu lembar formulir ICR lebih banyak daripada jumlah data yang termuat pada formulir OMR sehingga investasi scanner lebih kecil karena jumlah lembarnya tidak banyak (Namun ingat perlu dibarengi dengan penambahan sejumlah komputer dan operatornya untuk membantu verifikasi).
3. Jumlah image yang dihasilkan kecil sehingga jumlah kebutuhan storage lebih kecil (ini sebenarnya tergantung resolusi image, pada OMR image 100 dpi sudah cukup untuk diproses).
Risiko yang membuat ICR gagal atau terganggu (berdasarkan jumlah keluhan pada organisasi penulis)
1. Lembar yang tidak didesain dari awal dan mutu percetakan Lembar ICR yang terdistorsi bisa menjadikan gagal total (27%)
2. Listrik Mati (0% dari masalah yang ada) diterjemahkan sebagai belum terjadi
3. Scanner macet atau tidak berfungsi atau gagal install (malah tidak install driver) (25,8% dari masalah yang ada)
4. Operator yang tidak terampil (27,7%)
5. Virus komputer (0 % dari masalah yang ada) diterjemahkan sebagai belum ada
6. Template pembacaan ICR gagal membaca (8% dari masalah yang ada)
7. Responden salah isi atau tulisan tidak terbaca dengan baik akibat bentuk tidak wajar (10,4%)*
*Kondisi ini pada saat sudah dilakukan sosialisasi pengisian formulir.
Konsekuensi Memilih ICR
Tentunya sekarang apabila diputuskan penggunaan ICR konsekuensinya adalah : mendesain formulir dan mencetaknya membutuhkan kontrol kualitas tinggi dari sisi presisi, operator harus menguasai scanner untuk mendapatkan image yang optimal, operator menguasai ICR dan verifikasinya dilakukan beberapa komputer dan operator agar lebih cepat, perlu tenaga tune in template bila diperlukan, perlu sosialisasi pengisian formulir agar tulisannya bagus dan tertib serta pada tempatnya.
Konsekuensi memilih OMR
Kontrol kualitas cetak dari sisi warna, presisi. Sosialisasi pengisian lembar OMR. Penyediaan scanner yang memiliki kapasitas dan kemampuan besar per harinya, penanganan dokumen fisik yang teratur karena jumlah yang besar, penambahan storage apabila image hendak disimpan, dan pelatihan operator.
Pertimbangan memilih teknologi ini bagi organisasi berbeda-beda menurut tujuannya. Pada perbankan misalnya tidak mungkin nasabahnya diberi formulir OMR untuk menulis nama lengkap, alamat, nama ibu kandung, dsb sehingga malah membuat calon nasabah mundur takut direpotin. Pada Ujian multiple choice misalnya tidak bijaksana menggunakan teknologi ICR dimana para verificator memverifikasi jawaban A, B, C, D, E dari ribuan siswa, OMR jauh lebih cocok.
Wacana OMR untuk Tabulasi Nasional
Bagaimana bila wacana OMR digunakan untuk tabulasi 2009 ? Pertama perlu dipikirkan dulu azas legalitas dari form OMR itu apabila ini hanya digunakan untuk data entry dan tidak akan digunakan sebagai dasar perhitungan maka form C1-OMR akan diisi petugas TPS (Buku petunjuk pengisian dan Sosialisasi sangat penting) disertai form C1 DPR yang discan bersamaan, dimana form OMR sebagai alat input dan Form C1 bukti atau lampirannya. Kemudian jelas bahwa lembarannya mungkin meningkat 2-3 kali lipat banyaknya dari lembar ICR yang sekarang. Apabila ini dianggap sebagai dokumen legal maka disetiap lembar formulir OMR di TPS apakah harus ditanda tangan ? atau Cuma rangkumannya saja halaman depan?
Kemudian dengan volume peningkatan kertas 2-3 kali lipat apakah scanner yang tersedia masih sanggup dijalankan tanpa kehabisan suku cadang habis pakai atau consumables? Berarti perlu dibudgetkan adanya consumables cadangan. Kemudian apakah image di save dan dikirim ke pusat semuanya? Kalau iya berarti perlu scaling storage lebih besar.
Kemungkinan pekerjaan scanner akan mudah kalau pelatihan operatornya minimal 2-3 hari dengan praktek seperti yang dahulu pernah dilakukan penulis pada kegiatan training 400-an kabupaten untuk scanning lembar ujian UASBN.
Kemungkinan suksesnya memang lebih besar kalau semuanya well-planned. Namun kalau waktunya Cuma 2 pekan seperti kata tim IT KPU BPPT maka rasa-rasanya penulis juga pesimis harus menyiapkan cetakan dan kontrol kualitasnya, sosialisasi cara mengisi, dan sosialisasi penggunaan teknologi.
ICR pada Tabulasi Nasional
Untuk ICR form sebenarnya bukan sekedar ketebalan yang menjadi masalah namun bentuk mark type nya (kotak-kotak tempat angka ditulis) dapat menjadi bumerang pada kondisi miss-capturing lebih aman menggunakan raster atau warna (namun balik lagi, adalah dana tersedia untuk itu) yang dapat dihilangkan pada proses scanning.
Kemudian perlu sosialisasi mengenai cara mengisi formulir dan waktu pelatihan yang lebih lama dari satu hari. Kenapa lebih dari satu hari ? karena materi untuk mendapatkan image yang baik dari sebuah scanner membutuhkan waktu lama dan sangat tergantung fitur-fitur dari scanner.
Beban Psikologi dan Error
Bagaimana perhitungan beban psikologis anggota TPS yang mengisi lembar OMR? Kalau untuk masalah itu penulis memberikan tanggapan beban psikologis mau ditaruh disebelah mana ? Apakah di pundak anggota TPS atau operator ? Beban psikologis ditaruh di anggota TPS yang harus mengisi 10-20 lembar OMR Form setelah lelah merangkum hasil atau beban psikologis pada operator yang harus memvalidasi semua hasil C1-IT ? Keduanya ada beban psikologis, pada form OMR susahnya kita berikan pada yang mengisi, pada form ICR susahnya kita berikan pada yang memproses. Dan kalau bicara error yang terjadi, bisa saja si anggota TPS salah mengisi formulir OMR, atau bisa juga si operator lupa memvalidasi atau salah memvalidasi. Jadi bicara error yang terjadi atau beban psikologis rasa-rasanya keduanya berpeluang besar terjadi. Untuk error mungkin kita bisa berhitung, namun beban psikologi rasanya perlu di tes lebih lanjut dengan berbagai alat tes psikolog didampingi psikolog , mana yang scalingnya lebih stress . (mungkin alat tes MMPI-2 bisa digunakan : http://en.wikipedia.org/wiki/Minnesota_Multiphasic_Personality_Inventory).
Bagaimana dengan data entry manual, apakah lebih efektif dari ICR ? Penulis harus melihat kasusnya terlebih dahulu, apabila segalanya tidak terencana dengan baik, maka ICR akan memberikan akurasi yang rendah sehingga validasi menjadi sama beratnya dengan mengentry. Pada suatu implementasi di pengolahan aplikasi kartu kredit sebuah bank : mengentry secara manual 35-80 field pada aplikasi kartu kredit membutuhkan 40 operator yang terdiri dari tim entry dan tim validasi dengan optimal throughput 1,500 lembar per hari. Apabila digunakan ICR diperoleh angka 2,000 secara kolaboratif dengan 1 operator scanner dan 8 orang validator dengan akurasi yang kurang lebih sama. (Perlu diingat segalanya sudah dipersiapkan dengan ketat termasuk pengisian oleh sales kartu kredit – satu field = isian nama, alamat, kota dsb)
Namun penulis sepenuhnya sadar bahwa waktu 2 pekan tidaklah cukup untuk melakukan semua-semua yang ideal dan membuat penulis berpikir “Kenapa harus dua pekan ya?”. Anyaway at given condition, penulis merasa sangat kagum dengan semangat juang operator ICR di lapangan yang rela kurang tidur untuk membuat sistem ini berjalan. Di Jakarta Pusat dan Utara misalnya kegiatan scanning dimulai jam 2-3 malam setelah lembar C1 – IT terkumpul. Di malam (atau pagi ya) ini pulalah mereka mulai belajar praktek dan mencoba mengatasi hal-hal yang terjadi seperti kertas tipis, beda ukuran dan lain sebagainya dan tetap bersemangat.
Pihak yang memberikan usulan kepada KPU untuk menjalankan ICR (kabarnya bukan Tim TI lama dan bukan Tim IT BPPT) semestinya memberikan pula langkah persiapan yang memadai dari sisi desain formulir dan percetakannya, penambahan jumlah PC untuk operator validasi, dan estimasi waktu yang wajar untuk penyelesaian pekerjaan sehingga sistem ini tidak memberikan over expectation dan over confidence pada KPU. Pengurangan jumlah formulir dapat menjadikan cost benefit bagi KPU tetapi jangan lupa ada cost tambahan berupa tambahan investasi komputer dan operator disetiap daerah untuk melakukan validasi. Beban psikologis anggota TPS dikurangi namun jangan lupa ada beban psikologis pada operator ICR.
Penulis sadar bahwa Tim IT KPU BPPT telah mencoba yang terbaik dari segala keterbatasan yang terjadi, ibarat disuruh lomba lari dengan kaki terikat ditambah masih dihujat para penonton dari luar, sungguh membuat beban psikologis berpindah ke Tim IT KPU – BPPT. (Mungkin perlu ada topik penelitian aliran beban psikologis pada implementasi IT).
Jadi memilih OMR, ICR, atau Entry Manual merupakan pilihan yang harus dihitung konsekuensi dan persiapannya, mana yang tepat sangat tergantung pada tujuan yang ingin dicapai karena semuanya memiliki nilai plus dan minus. Namun perlu diingat jikalau memang sudah memutuskan teknologi mana yang dipilih tentunya segala konsekuensi dan kebutuhan untuk mencapai keberhasilannya perlu dipenuhi terlebih dahulu.
Demikian adalah tulisan penulis berdasarkan praktek yang terjadi pada beberapa proyek di Indonesia, segala masukan atas tulisan ini akan diterima dengan senang hati agar dapat memperkaya wawasan penulis. Marilah mensukseskan TI pemilu 2009 untuk legislatif maupun pilpres, apa pun teknologinya.Semoga pendapat penulis ini berguna untuk implementasi teknologi berikutnya di Indonesia.
Saking alotnya perdebatan itu, tim teknologi informasi KPU terbelah menjadi dua kubu. Aziz lebih memilih menggunakan ICR karena cocok dengan kondisi di lapangan. ICR lebih unggul dalam hal kecepatan perhitungan suara dan mudah dilakukan petugas. Hanya saja, Aziz berterus terang, memang ada yang meragukan kemampuan ICR untuk mendeteksi karakter angka tertentu. Angka seperti 1 dan 7, 3 dan 8, 6 dan 0 dalam tulisan tangan kadang-kadang memang hampir mirip. Tapi Aziz yakin, masalah itu telah teratasi. ''Sampai sejelek apa pun tulisan, karakternya masih bisa diidentifikasi,'' ujar Aziz.
Di sisi berlawanan, ada kelompok lain yang lebih memilih menggunakan teknologi optical mark recognition (OMR). Prinsipnya, OMR juga menjalankan fungsi pemindaian. Hanya saja, tak seperti ICR yang berusaha memindai tulisan tangan, OMR memindai data yang telah diberi tanda pada karakter abjad atau angka tertentu. ''Dengan cara ini, tingkat validitas dan akurasi data jelas lebih terjamin,'' kata Bambang Edi Leksono, pendukung metode OMR.
Penulis memandang bahwa dua teknologi tersebut sama-sama dapat berpeluang untuk sukses dijalankan pada tabulasi nasional Pemilu 2009,.Penulis melihat kedua pendapat di atas “benar” kecuali pada kata-kata “Sampai sejelek apa pun tulisan, karakternya masih bisa teridentifikasi” karena sampai sekarang ICR tercanggih pun belum pernah diimplementasikan untuk membaca resep obat dari seorang dokter disebuah apotik . (Itupun penulis masih ragu apakah kata-kata itu salah kutip atau memang demikian adanya, penulis tidak ingin berpolemik pada masalah tersebut).
Dari pengalaman penulis menjalankan ICR maupun OMR, mutlak diperlukan persiapan pelaksanaan yang cermat dan pendekatan yang berbeda pada masing-masing teknologi. Ibarat penulis berada di Klaten (kota kelahiran penulis yang terletak di antara Yogyakarta dan Solo/Surakarta) hendak terbang ke Jakarta, maka penulis harus memilih bandara Yogya Adi Sucipto atau Solo Adi Sumarmo. Untuk ke Yogya penulis harus menempuh jalan ke Gondang-Prambanan-Kalasan -Yogya sedangkan ke Solo penulis harus menempuh jalan ke Delanggu-Kartasura-Solo. Demikian pula pada kedua teknologi ini , keduanya membutuhkan pendekatan berbeda dalam mencapai tujuannya.
Optical Mark Recognition
OMR mengandalkan persentasi warna hitam (dari isian pensil/pena/spidol) pada suatu area tertentu yang akan dibaca sebagai data tertentu. Jadi seperti yang kita lihat pada lembar ujian UAN / UASBN / Rekrutmen berbentuk multiple choice, apabila kita mengarsir atau memberi tanda silang pada pilihan jawaban “A” maka aplikasi OMR akan membacanya sebagai “A”.

Gambar 1. Proses Lembar OMR dapat dilakukan dengan tanda silang dengan pena, pensil dan spidol yang penting image yang dihasilkan cukup hitam.
Mengapa penulis katanya produk OMR luar negeri tidak akan menang melawan produk OMR dalam negeri di Indonesia ? Karena persiapan pelaksanaan OMR di Indonesia biasanya memang lain daripada yang lain: Salah cetak formulir baik : salah ukuran, salah warna, salah potong hampir selalu terjadi di Indonesia, sehingga produsen OMR di dalam negeri pada awalnya bersusah payah melakukan re-engineering mengatasi hal ini. Belum lagi masalah salah pengisian nomor peserta, anulir nilai soal, isian pensil tipis-tipis, sosialisasi pengisian yang biasanya kurang baik atau mungkin ada satu-dua orang yang benar-benar tidak mengerti cara mengisinya biarpun disosialisasi berkali-kali.Apabila lembar ujian habis ? Mereka akan melakukan fotocopy lembar jawaban sebagai pengganti. Sederhana sekali.
Pada persiapan lembar ujian di luar negeri, penulis mengacu pada negeri tetangga Singapura, mereka mencetak dengan mesin cetak continuous form dengan presisi tinggi, menggunakan color drop out ink, yang mahalnya ampun-ampunan.Tidak menggunakan fotocopy. Aplikasi luar negeri di desain pada kondisi ideal seperti ini, makanya beberapa merk software OMR luar negeri berguguran di negeri ini karena tidak sanggup mengatasi lingkungan yang kurang terantisipasi oleh mereka. Berbanggalah saudara-saudara bahwa OMR buatan dalam negeri jauh lebih bandel…. karena memang lingkungan kita benar-benar bandel. (Ini diakui oleh seorang direktur ICR dari mancanegara dan rekan-rekan distributor scanner se Asia sewaktu penulis memperagakan salah satu software OMR dari Indonesia dengan segala kendala yang terjadi. Saat ini software ini digunakan di 3 negara Malaysia, Korea Selatan, dan Arab Saudi).
Bagaimana agar OMR sukses dalam implementasinya ?
1. Desain formulir OMR yang minim resiko. (maksudnya resiko salah warna, salah cetak, bulatan jawaban cukup jaraknya antara satu pilihan dengan pilhan lain, dan bulatan pilihan cukup besar agar tidak menyebrang ke pilihan tetangga ketika mengisi, gunakan mode dua warna cetak antara anchor (hitam) dan objek yang diisi (merah, biru, hijau – scanner mampu mendropout warna ini).
2. Sosialisasikan cara mengisi Lembar OMR dengan baik, berupa petunjuk pengisian maupun diperagakan cara pengisiannya sebagai contoh.
3. Lembar jangan sampai kotor, robek atau terlipat pada saat pengumpulan dan jangan sekali-kali distaples.
4. Kecepatan scanner sangat mempengaruhi proses OMR karena aplikasinya cenderung membaca lebih cepat daripada kecepatan scanner.
Bagaimana Kelemahan dari OMR ?
1. Keengganan Responden mengisi pada isian yang cukup banyak pada satu form.
Untuk mengisi nama lengkap, alamat, nama kota, nama propinsi dan deskripsi panjang memang tidak cocok menggunakan OMR, karena dapat membuat respondennya frustasi. Pada ujian sangat cocok untuk menggunakan OMR.
Mengisi lembar OMR pun membutuhkan waktu yang lebih lama.
2. Data yang dapat diperoleh dari suatu formulir OMR terbatas jumlahnya. Sehingga untuk data yang banyak diperlukan lembar yang banyak pula. Sehingga untuk keperluan ini scannernya perlu lebih banyak atau kapasitasnya lebih besar.
Bagaimana Keunggulan dari OMR?
1. Waktu Proses yang cepat dan akurasi yang sangat tinggi
Karena logika aplikasi yang hanya mengecek “hitam” atau “putih” pada area tertentu, maka prosesnya cenderung cepat dan akurat. Akurat disini artinya bahwa isian yang diisi oleh responden akan diterjemahkan secara benar. (artinya kalau respondennya salah isi, bukan dalam lingkup hitungan akurasi)
2. Operator scanner lebih nyaman dan lebih cepat dalam bekerja karena sangat minim verifikasi
Pengalaman penulis untuk memproses 115,000 peserta ujian psikotes hanya membutuhkan waktu 4 jam dengan scanner kecepatan 100 ppm sebanyak 2 unit dengan 2 operator dan 2 pembantu operator yang mengurus kertasnya (masih ditambah dua orang lagi yang sibuk membelikan makanan dan membuatkan kopi dan teh).
3. Target penyelesaian pekerjaan dapat terukur dengan baik
Pada proyek OMR, penulis dapat menentukan kapan pekerjaan diselesaikan dengan perkiraan yang tidak rumit. Bila ingin selesai 4 jam maka scanner yang dibutuhkan pada kecepatan sekian adalah sekian banyak ditambah beberapa operator.
Bagaimana Risiko yang membuat OMR gagal atau terganggu (berdasarkan jumlah keluhan pada organisasi penulis)
1. Lembar yang tidak didesain dari awal dan mutu percetakan Lembar OMR yang keterlaluan asal-asalannya (35% dari masalah yang ada)
2. Listrik Mati (3,5% dari masalah yang ada)
3. Scanner macet atau tidak berfungsi atau gagal install (malah tidak install driver) (28% dari masalah yang ada)
4. Operator yang tidak terampil, gampang ngambek , dan tidak datang tepat waktu atau malah bolos ( 1 % dari masalah yang ada)
5. Virus komputer (2,8 % dari masalah yang ada)
6. Salah memilih template pembacaan OMR (28% dari masalah yang ada)
7. Lupa atau kehilangan dongle lisensi OMR sehingga tidak bisa berjalan aplikasinya.(0,5 % dari masalah yang ada)
Inti dari Optical Mark Recognition adalah susah diawal (mengisi formulir nya) tetapi tidak repot di akhir (operator yang memproses).Optical Mark Recognition juga memiliki risiko kegagalan yang rendah apabila cara pengisiannya tersosialisasikan dengan baik.
Intelligent Character Recognition (ICR)
Intelligent Character Recognition adalah teknologi mengenali tulisan tangan manusia yang serupa mungkin dengan huruf cetak (hand printing) dari sebuah image dan diterjemahkan menjadi data. Ini adalah definisi bagi penulis secara sederhana.
Secara awam , aplikasi ini menerjemahkan suatu image , setelah melalui pemisahan huruf demi huruf (separasi), menjadi suatu teks dalam format digital. Image ini dihasilkan dari lembar ICR yang discan menjadi image atau citra digital.
Kebetulan penulis pernah melakukan implementasi ICR dengan salah satu software ICR Internasional pada riset dan proses aplikasi kartu kredit berbasis alphanumeric ICR pada organisasi di Indonesia. Berbeda dengan OMR yang langsung didapatkan data dengan akurasi tinggi, ICR membutuhkan verifikasi dan validasi dari operator pada hasil-hasil yang meragukan.

Gambar 2. Implementasi Teknologi ICR di sebuah lembar biodata pada satu organisasi pemerintah
Bagaimana agar ICR sukses dalam implementasinya ?
1. Desain Formulir ICR yang rendah risiko (Membuat kotak huruf isian cukup besar, kotak huruf isian dapat dihilangkan pada saat scanning sehingga tidak mengganggu pembacaan ICR, Cetakan yang stabil, dan petunjuk pengisian yang jelas).
2. Kualitas cetakan formulir yang bermutu tinggi.
3. Kualitas image yang sangat jelas menjadi tolak ukur penting bagi proses ICR, teknologi ini menganalisa pattern atau bentuk citra mana yang sesuai dengan huruf atau angka mana, berbeda dengan OMR yang hanya mengukur hitam atau putih. Kualitas image didapatkan dari kualitas image scanner dan setting yang tepat sewaktu scanning.
4. Sosialisasi pengisian formulir ICR. Perlu diingatkan pada responden bahwa ICR memiliki keterbatasan dalam membaca tulisan mereka, sehingga kepatuhan mereka pada petunjuk pengisian akan menjadi kunci sukses implementasi.
5. Kecakapan operator ICR mulai dari ketrampilan mengoperasikan scanner pada kondisi kertas yang berbeda , mengoperasikan ICR , melakukan verifikasi dan validasi data.
6. Jumlah verifikator untuk implementasi harus banyak untuk mencapai target penyelesaian yang cepat, sehingga disini jumlah orang yang melakukan verifikasi menjadi kunci utama kecepatan ICR. Jadi kalau OMR perlu scanner cepat, ICR perlu komputer untuk verifikasi yang banyak, pada pengolahan skala besar. Pengalaman penulis untuk mencapai hasil 2000 lembar aplikasi kartu kredit (35-80 field) per hari dibutuhkan 1 operator scanner dan 8 orang verifikator dengan akurasi mendekati 98%.
7. Mekanisme verifikasi menjadi penting untuk mempercepat proses bagi aplikasi ICR, sehingga perlu dibuatkan interface yang memudahkan melakukan verifikasi.
8. Perlu kontrol kualitas akhir pada hasil untuk mencapai 100% Acccuracy.
9. Target waktu penyelesaian sukar diukur terutama pada awal proses, namun mulai biasanya mulai dapat diukur setelah 2-3 hari implementasi tergantung kerumitan formulir dan kemampuan operator.
Bagaimana Kelemahan dari ICR ?
1. Faktor akurasi awal tergantung dari berbagai variabel antara lain bentuk tulisan, pemilihan bentuk formulir, image yang dihasilkan oleh scanner yang harus menunjang ketajaman dan keutuhan bentuk pattern dari huruf atau angka. Faktor akurasi berikutnya sangat tergantung dari sikap mental operator yang teliti dan telaten dalam menjalankan proses ICR. Disini prosesnya tidak bisa terlalu dipaksakan untuk cepat untuk mencapai akurasi tinggi.
2. Operator yang berfungsi sebagai verifikator dan validator (apalagi yang biasa mengoperasikan OMR) akan cepat stress dan malas apabila hasil yang harus diverifikasi sangat banyak. Pelatihan intensif yang mencakup pengendalian image hasil scanner, pengoperasian ICR dan Verifikasi harus dilakukan dengan praktek yang cukup.
3. Perlu banyak orang untuk mengoperasikan komputer yang membantu proses verifikasi pada ICR.
4. Kadang diperlukan re-tune in data pada saat implementasi. Mengapa demikian? Berbeda dengan proses OMR pada field kode kota dalam 3 angka misalnya responden dipaksa mengarsir pada angka 0-9, sedangkan pada ICR disediakan kotak kosong sebanyak 3 buah yang diisi angka 0-9, namun pada banyak kasus sering diisi dengan kata “JKT”. Pada kasus ini template ICR harus dimodifikasi untuk memenuhi dua kriteria yang ada, mengapa begitu ? Karena yang salah dapat mencapai 30-40% dari responden, mengapa begitu ? Kembali ke topik awal tadi bahwa : “sosialisasi pengisian yang biasanya kurang baik atau mungkin ada satu-dua orang yang benar-benar tidak mengerti cara mengisinya biarpun disosialisasi berkali-kali”.
Keunggulan ICR
1. Mengisi formulir ICR itu mudah dibanding formulir OMR
2. Jumlah data yang termuat dalam satu lembar formulir ICR lebih banyak daripada jumlah data yang termuat pada formulir OMR sehingga investasi scanner lebih kecil karena jumlah lembarnya tidak banyak (Namun ingat perlu dibarengi dengan penambahan sejumlah komputer dan operatornya untuk membantu verifikasi).
3. Jumlah image yang dihasilkan kecil sehingga jumlah kebutuhan storage lebih kecil (ini sebenarnya tergantung resolusi image, pada OMR image 100 dpi sudah cukup untuk diproses).
Risiko yang membuat ICR gagal atau terganggu (berdasarkan jumlah keluhan pada organisasi penulis)
1. Lembar yang tidak didesain dari awal dan mutu percetakan Lembar ICR yang terdistorsi bisa menjadikan gagal total (27%)
2. Listrik Mati (0% dari masalah yang ada) diterjemahkan sebagai belum terjadi
3. Scanner macet atau tidak berfungsi atau gagal install (malah tidak install driver) (25,8% dari masalah yang ada)
4. Operator yang tidak terampil (27,7%)
5. Virus komputer (0 % dari masalah yang ada) diterjemahkan sebagai belum ada
6. Template pembacaan ICR gagal membaca (8% dari masalah yang ada)
7. Responden salah isi atau tulisan tidak terbaca dengan baik akibat bentuk tidak wajar (10,4%)*
*Kondisi ini pada saat sudah dilakukan sosialisasi pengisian formulir.
Konsekuensi Memilih ICR
Tentunya sekarang apabila diputuskan penggunaan ICR konsekuensinya adalah : mendesain formulir dan mencetaknya membutuhkan kontrol kualitas tinggi dari sisi presisi, operator harus menguasai scanner untuk mendapatkan image yang optimal, operator menguasai ICR dan verifikasinya dilakukan beberapa komputer dan operator agar lebih cepat, perlu tenaga tune in template bila diperlukan, perlu sosialisasi pengisian formulir agar tulisannya bagus dan tertib serta pada tempatnya.
Konsekuensi memilih OMR
Kontrol kualitas cetak dari sisi warna, presisi. Sosialisasi pengisian lembar OMR. Penyediaan scanner yang memiliki kapasitas dan kemampuan besar per harinya, penanganan dokumen fisik yang teratur karena jumlah yang besar, penambahan storage apabila image hendak disimpan, dan pelatihan operator.
Pertimbangan memilih teknologi ini bagi organisasi berbeda-beda menurut tujuannya. Pada perbankan misalnya tidak mungkin nasabahnya diberi formulir OMR untuk menulis nama lengkap, alamat, nama ibu kandung, dsb sehingga malah membuat calon nasabah mundur takut direpotin. Pada Ujian multiple choice misalnya tidak bijaksana menggunakan teknologi ICR dimana para verificator memverifikasi jawaban A, B, C, D, E dari ribuan siswa, OMR jauh lebih cocok.
Wacana OMR untuk Tabulasi Nasional
Bagaimana bila wacana OMR digunakan untuk tabulasi 2009 ? Pertama perlu dipikirkan dulu azas legalitas dari form OMR itu apabila ini hanya digunakan untuk data entry dan tidak akan digunakan sebagai dasar perhitungan maka form C1-OMR akan diisi petugas TPS (Buku petunjuk pengisian dan Sosialisasi sangat penting) disertai form C1 DPR yang discan bersamaan, dimana form OMR sebagai alat input dan Form C1 bukti atau lampirannya. Kemudian jelas bahwa lembarannya mungkin meningkat 2-3 kali lipat banyaknya dari lembar ICR yang sekarang. Apabila ini dianggap sebagai dokumen legal maka disetiap lembar formulir OMR di TPS apakah harus ditanda tangan ? atau Cuma rangkumannya saja halaman depan?
Kemudian dengan volume peningkatan kertas 2-3 kali lipat apakah scanner yang tersedia masih sanggup dijalankan tanpa kehabisan suku cadang habis pakai atau consumables? Berarti perlu dibudgetkan adanya consumables cadangan. Kemudian apakah image di save dan dikirim ke pusat semuanya? Kalau iya berarti perlu scaling storage lebih besar.
Kemungkinan pekerjaan scanner akan mudah kalau pelatihan operatornya minimal 2-3 hari dengan praktek seperti yang dahulu pernah dilakukan penulis pada kegiatan training 400-an kabupaten untuk scanning lembar ujian UASBN.
Kemungkinan suksesnya memang lebih besar kalau semuanya well-planned. Namun kalau waktunya Cuma 2 pekan seperti kata tim IT KPU BPPT maka rasa-rasanya penulis juga pesimis harus menyiapkan cetakan dan kontrol kualitasnya, sosialisasi cara mengisi, dan sosialisasi penggunaan teknologi.
ICR pada Tabulasi Nasional
Untuk ICR form sebenarnya bukan sekedar ketebalan yang menjadi masalah namun bentuk mark type nya (kotak-kotak tempat angka ditulis) dapat menjadi bumerang pada kondisi miss-capturing lebih aman menggunakan raster atau warna (namun balik lagi, adalah dana tersedia untuk itu) yang dapat dihilangkan pada proses scanning.
Kemudian perlu sosialisasi mengenai cara mengisi formulir dan waktu pelatihan yang lebih lama dari satu hari. Kenapa lebih dari satu hari ? karena materi untuk mendapatkan image yang baik dari sebuah scanner membutuhkan waktu lama dan sangat tergantung fitur-fitur dari scanner.
Beban Psikologi dan Error
Bagaimana perhitungan beban psikologis anggota TPS yang mengisi lembar OMR? Kalau untuk masalah itu penulis memberikan tanggapan beban psikologis mau ditaruh disebelah mana ? Apakah di pundak anggota TPS atau operator ? Beban psikologis ditaruh di anggota TPS yang harus mengisi 10-20 lembar OMR Form setelah lelah merangkum hasil atau beban psikologis pada operator yang harus memvalidasi semua hasil C1-IT ? Keduanya ada beban psikologis, pada form OMR susahnya kita berikan pada yang mengisi, pada form ICR susahnya kita berikan pada yang memproses. Dan kalau bicara error yang terjadi, bisa saja si anggota TPS salah mengisi formulir OMR, atau bisa juga si operator lupa memvalidasi atau salah memvalidasi. Jadi bicara error yang terjadi atau beban psikologis rasa-rasanya keduanya berpeluang besar terjadi. Untuk error mungkin kita bisa berhitung, namun beban psikologi rasanya perlu di tes lebih lanjut dengan berbagai alat tes psikolog didampingi psikolog , mana yang scalingnya lebih stress . (mungkin alat tes MMPI-2 bisa digunakan : http://en.wikipedia.org/wiki/Minnesota_Multiphasic_Personality_Inventory).
Bagaimana dengan data entry manual, apakah lebih efektif dari ICR ? Penulis harus melihat kasusnya terlebih dahulu, apabila segalanya tidak terencana dengan baik, maka ICR akan memberikan akurasi yang rendah sehingga validasi menjadi sama beratnya dengan mengentry. Pada suatu implementasi di pengolahan aplikasi kartu kredit sebuah bank : mengentry secara manual 35-80 field pada aplikasi kartu kredit membutuhkan 40 operator yang terdiri dari tim entry dan tim validasi dengan optimal throughput 1,500 lembar per hari. Apabila digunakan ICR diperoleh angka 2,000 secara kolaboratif dengan 1 operator scanner dan 8 orang validator dengan akurasi yang kurang lebih sama. (Perlu diingat segalanya sudah dipersiapkan dengan ketat termasuk pengisian oleh sales kartu kredit – satu field = isian nama, alamat, kota dsb)
Namun penulis sepenuhnya sadar bahwa waktu 2 pekan tidaklah cukup untuk melakukan semua-semua yang ideal dan membuat penulis berpikir “Kenapa harus dua pekan ya?”. Anyaway at given condition, penulis merasa sangat kagum dengan semangat juang operator ICR di lapangan yang rela kurang tidur untuk membuat sistem ini berjalan. Di Jakarta Pusat dan Utara misalnya kegiatan scanning dimulai jam 2-3 malam setelah lembar C1 – IT terkumpul. Di malam (atau pagi ya) ini pulalah mereka mulai belajar praktek dan mencoba mengatasi hal-hal yang terjadi seperti kertas tipis, beda ukuran dan lain sebagainya dan tetap bersemangat.
Pihak yang memberikan usulan kepada KPU untuk menjalankan ICR (kabarnya bukan Tim TI lama dan bukan Tim IT BPPT) semestinya memberikan pula langkah persiapan yang memadai dari sisi desain formulir dan percetakannya, penambahan jumlah PC untuk operator validasi, dan estimasi waktu yang wajar untuk penyelesaian pekerjaan sehingga sistem ini tidak memberikan over expectation dan over confidence pada KPU. Pengurangan jumlah formulir dapat menjadikan cost benefit bagi KPU tetapi jangan lupa ada cost tambahan berupa tambahan investasi komputer dan operator disetiap daerah untuk melakukan validasi. Beban psikologis anggota TPS dikurangi namun jangan lupa ada beban psikologis pada operator ICR.
Penulis sadar bahwa Tim IT KPU BPPT telah mencoba yang terbaik dari segala keterbatasan yang terjadi, ibarat disuruh lomba lari dengan kaki terikat ditambah masih dihujat para penonton dari luar, sungguh membuat beban psikologis berpindah ke Tim IT KPU – BPPT. (Mungkin perlu ada topik penelitian aliran beban psikologis pada implementasi IT).
Jadi memilih OMR, ICR, atau Entry Manual merupakan pilihan yang harus dihitung konsekuensi dan persiapannya, mana yang tepat sangat tergantung pada tujuan yang ingin dicapai karena semuanya memiliki nilai plus dan minus. Namun perlu diingat jikalau memang sudah memutuskan teknologi mana yang dipilih tentunya segala konsekuensi dan kebutuhan untuk mencapai keberhasilannya perlu dipenuhi terlebih dahulu.
Demikian adalah tulisan penulis berdasarkan praktek yang terjadi pada beberapa proyek di Indonesia, segala masukan atas tulisan ini akan diterima dengan senang hati agar dapat memperkaya wawasan penulis. Marilah mensukseskan TI pemilu 2009 untuk legislatif maupun pilpres, apa pun teknologinya.Semoga pendapat penulis ini berguna untuk implementasi teknologi berikutnya di Indonesia.
Selasa, 21 April 2009
Pemilihan Teknologi Data Entry
Pada saat dihadapkan pada kegiatan entry data sebanyak ribuan atau bahkan jutaan lembar dalam waktu tertentu, organisasi harus memilih cara entry data yang cocok dengan target organisasi. Pada dasarnya proses entry data dibedakan menjadi dua kategori besar yaitu people input atau sering disebut sebagai manual input atau automatic input yang sering juga disebut sebagai form processing. People input dapat menggunakan berbagai device seperti komputer , telpon genggam dengan sms, dan alat lain dengan aplikasi input data dan jaringan yang mendukung. Kemudian form processing sendiri memiliki berbagai teknologi yang mendukung antara lain : Optical Character Recognition (OCR), Barcode Recognition (IBR), Intelligent Character Recognition (ICR), dan Optical Mark Recognition (OMR).
Faktor yang perlu diperhitungkan dalam memilih teknologi
Dalam memilih organisasi perlu mendefinisikan target pencapaian data entry. Beberapa faktor yang dapat dipertimbangkan dalam menyelaraskan tujuan data entry dengan pilihan metodenya antara lain:
1. Integritas Data dan Akurasi Data
Apabila suatu data dikumpulkan untuk memberikan gambaran besar suatu populasi tanpa membutuhkan akurasi yang tinggi, maka organisasi dapat mempertimbangkan teknologi yang memberikan akurasi standar dengan pengirim data yang tidak perlu terlalu dipertanyakan integritasnya, misalnya pada riset-riset ringan seperti pemilihan idol pada televisi, pengiriman riset mengenai pendapat pada suatu masalah, keluhan dari customer dan lain sebagainya. Untuk kepentingan ini biasanya dipilih teknologi sms , web polling, dan beberapa cara lainnya. Disini responden dapat diajak berpartisipasi mengentry data langsung ke system.
Untuk suatu data yang memang direncanakan diambil dengan integritas data yang dapat dipertanggungjawabkan maka harus dipilih metode pengumpulan data dimana sang pengirim data atau responden harus diketahui identitasnya dengan pasti. Misalnya survey yang dilakukan petugas pengumpul data, pencatatan meteran listrik dan air, pengumpulan data calon nasabah kartu kredit oleh surveyor, formulir permintaan paspor, ujian massal dan sebagainya. Ada metode ini dapat dilakukan metode pengumpulan data yang tertutup menggunakan form processing atau input data manual dengan keamanan tertentu. Apabila kita menggunakan web atau sms untuk menangani data ini, biasanya perlu verifikasi identitas pembuat data atau respondennya.
2. Kecepatan proses data
Apabila dibutuhkan kecepatan proses data yang tinggi maka pilihan data entry ada pada dua metode yaitu manual entry oleh responden langsung ke dalam sistem dan juga automatic form processing. Untuk mencatat transaksi perbankan misalnya sang nasabah mengentry data kedalam sistem perbankan yang dinamakan online banking, dengan sistem ini satu bank dapat melayani ratusan hingga jutaan nasabah yang hendak melakukan transaksi. Untuk ujian ratusan hingga ribuan bahkan jutaan peserta tes, organisasi dapat menggunakan optical mark recognition (OMR) sehingga hasilnya dapat diketahui dalam beberapa jam. Untuk mengentry data calon nasabah kartu kredit , organisasi dapat menggunakan teknologi Intelligent Character Recognition (ICR) yang kemudian diverifikasi oleh verifier.
3. Bentuk Data
Apabila data yang harus dientry jumlahnya banyak dan satu field datanya memuat informasi yang banyak dalam satu formulir, maka penggunaan device sms menjadi tidak efektif dilakukan. Demikian pula pada teknologi OMR, menulis data panjang seperti alamat , nama kota lahir, dalam jumlah besar biasanya membutuhkan lembar yang banyak, pada suatu situasi, penggunaan OMR menjadi tidak efisien. Misalnya apabila teknologi OMR digunakan untuk menampung data calon nasabah kartu kredit, maka hal ini tidak tepat mengingat cara mengisi data yang lama dan penggunaan lembar yang banyak. Sebaliknya OMR efektif menangani data yang terbatas pilihannya , seperti ujian atau kuesioner dengan jawaban multiple choice, atau data yang menampung angka saja atau huruf terbatas.
4. Ketersediaan Infrastruktur dan piranti pendukung
Untuk polling menggunakan sms dan internet misalnya, perlu diyakinkan ketersediaan device dan juga jaringannya. Untuk penggunaan OMR, ICR, IBR dengan scanner, perlu diyakinkan kesiapan scanner, komputer dan formulir yang sebelumnya telah dirancang untuk teknologi tersebut dengan risiko minimal dan pencetakan formulir yang benar.
5. Petunjuk yang jelas kepada responden dan/atau pengumpul data
Bagaimana SMS harus dikirimkan ? Bagaimana Mengisi data dalam webform? Bagaimana mengisi lembar jawaban OMR ? Bagaimana mengisi formulir ICR ? Hal ini harus disosialisasikan terlebih dahulu, agar data yang sudah dikirimkan atau dibuat tidak mubazir karena tidak dapat diolah menjadi informasi yang diharapkan.
Untuk teknologi manual entry lebih tolerant terhadap kesalahan pengisian, karena ada manusia yang melakukan entry terhadap formulir yang diisi. Teknologi automated processing , akan menimbulkan masalah bila diisi asal-asalan tanpa batasan.
7. Kemampuan Operator Teknologi
Penggunaan teknologi scanner untuk para operator yang belum pernah mendapatkan pelatihan intensif akan menimbulkan kesulitan luar biasa dalam pengumpulan data. Karena biasanya yang terjadi dilapangan adalah distorsi dari kondisi ideal yang direncanakan di awal, misalnya kertas lembar OMR/ICR tidak sama dengan yang didesain dari awal baik dari sisi ukuran, bentuk maupun kondisinya. Penggunaan webform untuk operator yang kurang fasih menggunakan aplikasi webbased atau komputer juga akan menimbulkan kesulitan tersendiri dalam pengumpulan data.
Koreksi Ujian Massal dalam waktu singkat
Sebuah organisasi meminta penulis mengkoreksi ujian sebanyak 116 ribu pelamar yang nilai nya harus diumumkan dalam waktu 1 hari setelah ujian. Penulis memilih teknologi Mark Reader dengan pertimbangan ujian tersebut menggunakan metode multiple choice atau pilihan ganda dan pertimbangan bahwa OMR membutuhkan verifikasi yang minimal dalam pelaksanaannya.
Penulis kemudian melakukan desain formulir yang pencetakannya diawasi secara ketat dari kualitas warna, ketebalan kertas, ukuran kertas dan teknik pemotongan kertas yang dicetak. Panitia ujian berkomitmen untuk melakukan sosialisasi cara mengisi lembar jawaban dengan tanda silang pada lembar OMR sebelum ujian dilakukan. Output laporannya pun disetujui di awal pelaksanaan sehingga sewaktu operasional tidak perlu lagi memikirkan bentuk data output.
Pada waktu pelaksanaan semua lembarjawab dikumpulkan kembali dan diatur rapi menurut warna masing – masing lembar jawaban oleh panitia, karena telah disepakati bahwa lembar berbeda memiliki kunci jawaban yang berbeda dan output setiap populasinya dipisahkan dengan populasi lainnya untuk mendapatkan statistik yang tepat untuk soal yang dibagaikan.
Tim dari penulis menggunakan 2 buah scanner, masing-masing kecepatan 100 lembar per menit dan 60 lembar per menit dengan software Mark Reader berkecepatan pembacaan 2500/menit dengan tim operasi 6 orang, 2 operator scanner dan 4 bertanggung jawab pada arus kertas.
Pekerjaan diselesaikan dalam waktu 6 jam dari pukul 10.00 malam hingga pukul 04.00 pagi dini hari dan diumumkan oleh panitia setelah melalui tahap cek ricek pada pukul 15.00.
Kunci pada implementasi OMR adalah perencanaan yang baik pada formulir, kemampuan operator, kapasitas scanner dan perencanaan output.
Teknologi Input Data dengan Flexible Layout OCR/ICR
Salah satu organisasi hendak menangkap data pada Invoice-Invoice yang dikirimkan oleh customer mereka dan kemudian diinput pada sistem yang online dengan bea cukai untuk pelaporan ekspor impor. Waktu untuk menginput data secara manual untuk satu invoice dengan jumlah 300 lembar dengan 3000 items adalah 4 hari kerja oleh 1 (satu) operator.
Penulis menyarankan implementasi Flexible Layout OCR dengan scanner ADF untuk mengotomatisasi data entry. Flexible Layout OCR adalah suatu aplikasi yang mampu menangkap data pada semi structured document yaitu dokumen yang mengandung informasi yang sama namun layout nya berbeda antara satu dokumen dengan dokumen lainnya. Keunggulan Flexible Layout OCR adalah perintah yang mudah kepada aplikasi untuk mencari data-data tertentu dengan tepat pada semi structured documents.
Penulis kemudian meminta sample beberapa jenis invoice dari customer yang berbeda (supaya aplikasi dapat menangkap lebar variasi dari letak data pada setiap invoice) , dari sampel tersebut dibuat suatu template untuk menangkap data pada dokumen-dokumen tersebut.
Pelaksanaan pada awalnya kurang lancar, dikarena dokumen yang diproses lebih bervariasi dari sampel yang diberikan sehingga diperlukan usaha tune-in template hingga tiga minggu untuk mencapai hasil yang maksimal. (maksimal = minimal verifikasi). Saat ini untuk memproses data invoice sebanyak 300 lembar dibutuhkan waktu selama 5 menit dengan akurasi tinggi.
Kunci pada implementasi Flexilayout OCR adalah sampel yang cukup mewakili pada saat mendesign template, kualitas image yang dihasilkan scanner, kemampuan operator mensetting scanner, kapasitas scanner, sosialisasi pengisian dan perencanaan output.
Data Entry dengan menggunakan ICR
Penulis membantu suatu organisasi untuk memproses aplikasi kartu kredit dengan tulisan tangan. Pada awalnya tim dari penulis menolak memproses aplikasi tersebut karena risiko yang besar akibat formulir tersebut sebenarnya tidak well designed untuk proses ICR sehingga penulis kuatir akan terlalu banyak verifikasi yang dilakukan. Namun setelah ada klarifikasi bahwa formulir baru akan dibuat berdasarkan usulan dari tim penulis maka implementasi ICR dapat disetujui.
Banyak kesalahpahaman bahwa teknologi ICR dapat membaca tulisan tangan orang dengan akurasi yang tinggi seberapa jeleknya pun tulisan orang tersebut. Perlu klarifikasi bahwa ICR tidak diciptakan untuk membaca tulisan tangan manusia yang jelek, ICR diciptakan untuk membaca tulisan tangan orang dalam range kualitas tertentu dimana satu huruf dapat dibedakan huruf lain dengan jelas, satu huruf terpisah dengan huruf lain dengan jelas dan satu huruf memiliki bentuk standar dengan penyimpangan yang minimal dari suatu standar. Itulah mengapa di aplikasi ICR dalam petunjuk pengisiannya ditulis : ditulis dengan huruf cetak. Jadi tidak tepat menggunakan ICR untuk membaca resep obat dokter misalnya.
Dalam implementasi ICR yang perlu diperhatikan adalah formulir harus memenuhi kaidah pembacaan ICR dengan risiko paling minimal, ketajaman hasil scanner, kemampuan operator, perlunya verifikasi intensif , validasi data dan pengumpulan output.
Saat ini sistem ICR di organisasi tersebut berjalan dengan produktivitas mencapai 3000 lembar/hari dengan 5 operator. (1 formulir ICR nya mencapai lebih dari 35 field).
Kunci dari implementasi ICR adalah persiapan lembar ICR yang rendah risiko, cetakan ICR berkualitas tinggi, kapasitas dan kualitas image scanner yang memadai, kecakapan operator ICR, sosialisasi pengisian dan perencanaan output yang baik.
Data Entry dengan menggunakan Barcode
Cara ini umum digunakan di pusat perbelanjaan, tracking logistik dan absensi karyawan. Yang menarik adalah penggunaan barcode untuk menyimpan 255 karakter seperti QR Code di Jepang dan beberapa implementasi di Indonesia.
Misalnya di pusat perbelanjaan buah-buahan, dimana timbangan/neraca disertai keyboard numeric , penimbang mengisi kode produk dan muncul stiker barcode dari printer kecil disebelah timbangan. Barcode tersebut mencatat nomor kode produk dan beratnya, sehingga ketika di scanning di mesin kasir, kode produk dan beratnya otomatis muncul dilayar.
Kunci dari implementasi Barcode adalah persiapan data base barcode, cetak barcode berkualitas dan aplikasi pengenal barcode yang mampu mendeteksi pada kondisi terdistorsi.
Faktor yang perlu diperhitungkan dalam memilih teknologi
Dalam memilih organisasi perlu mendefinisikan target pencapaian data entry. Beberapa faktor yang dapat dipertimbangkan dalam menyelaraskan tujuan data entry dengan pilihan metodenya antara lain:
1. Integritas Data dan Akurasi Data
Apabila suatu data dikumpulkan untuk memberikan gambaran besar suatu populasi tanpa membutuhkan akurasi yang tinggi, maka organisasi dapat mempertimbangkan teknologi yang memberikan akurasi standar dengan pengirim data yang tidak perlu terlalu dipertanyakan integritasnya, misalnya pada riset-riset ringan seperti pemilihan idol pada televisi, pengiriman riset mengenai pendapat pada suatu masalah, keluhan dari customer dan lain sebagainya. Untuk kepentingan ini biasanya dipilih teknologi sms , web polling, dan beberapa cara lainnya. Disini responden dapat diajak berpartisipasi mengentry data langsung ke system.
Untuk suatu data yang memang direncanakan diambil dengan integritas data yang dapat dipertanggungjawabkan maka harus dipilih metode pengumpulan data dimana sang pengirim data atau responden harus diketahui identitasnya dengan pasti. Misalnya survey yang dilakukan petugas pengumpul data, pencatatan meteran listrik dan air, pengumpulan data calon nasabah kartu kredit oleh surveyor, formulir permintaan paspor, ujian massal dan sebagainya. Ada metode ini dapat dilakukan metode pengumpulan data yang tertutup menggunakan form processing atau input data manual dengan keamanan tertentu. Apabila kita menggunakan web atau sms untuk menangani data ini, biasanya perlu verifikasi identitas pembuat data atau respondennya.
2. Kecepatan proses data
Apabila dibutuhkan kecepatan proses data yang tinggi maka pilihan data entry ada pada dua metode yaitu manual entry oleh responden langsung ke dalam sistem dan juga automatic form processing. Untuk mencatat transaksi perbankan misalnya sang nasabah mengentry data kedalam sistem perbankan yang dinamakan online banking, dengan sistem ini satu bank dapat melayani ratusan hingga jutaan nasabah yang hendak melakukan transaksi. Untuk ujian ratusan hingga ribuan bahkan jutaan peserta tes, organisasi dapat menggunakan optical mark recognition (OMR) sehingga hasilnya dapat diketahui dalam beberapa jam. Untuk mengentry data calon nasabah kartu kredit , organisasi dapat menggunakan teknologi Intelligent Character Recognition (ICR) yang kemudian diverifikasi oleh verifier.
3. Bentuk Data
Apabila data yang harus dientry jumlahnya banyak dan satu field datanya memuat informasi yang banyak dalam satu formulir, maka penggunaan device sms menjadi tidak efektif dilakukan. Demikian pula pada teknologi OMR, menulis data panjang seperti alamat , nama kota lahir, dalam jumlah besar biasanya membutuhkan lembar yang banyak, pada suatu situasi, penggunaan OMR menjadi tidak efisien. Misalnya apabila teknologi OMR digunakan untuk menampung data calon nasabah kartu kredit, maka hal ini tidak tepat mengingat cara mengisi data yang lama dan penggunaan lembar yang banyak. Sebaliknya OMR efektif menangani data yang terbatas pilihannya , seperti ujian atau kuesioner dengan jawaban multiple choice, atau data yang menampung angka saja atau huruf terbatas.
4. Ketersediaan Infrastruktur dan piranti pendukung
Untuk polling menggunakan sms dan internet misalnya, perlu diyakinkan ketersediaan device dan juga jaringannya. Untuk penggunaan OMR, ICR, IBR dengan scanner, perlu diyakinkan kesiapan scanner, komputer dan formulir yang sebelumnya telah dirancang untuk teknologi tersebut dengan risiko minimal dan pencetakan formulir yang benar.
5. Petunjuk yang jelas kepada responden dan/atau pengumpul data
Bagaimana SMS harus dikirimkan ? Bagaimana Mengisi data dalam webform? Bagaimana mengisi lembar jawaban OMR ? Bagaimana mengisi formulir ICR ? Hal ini harus disosialisasikan terlebih dahulu, agar data yang sudah dikirimkan atau dibuat tidak mubazir karena tidak dapat diolah menjadi informasi yang diharapkan.
Untuk teknologi manual entry lebih tolerant terhadap kesalahan pengisian, karena ada manusia yang melakukan entry terhadap formulir yang diisi. Teknologi automated processing , akan menimbulkan masalah bila diisi asal-asalan tanpa batasan.
7. Kemampuan Operator Teknologi
Penggunaan teknologi scanner untuk para operator yang belum pernah mendapatkan pelatihan intensif akan menimbulkan kesulitan luar biasa dalam pengumpulan data. Karena biasanya yang terjadi dilapangan adalah distorsi dari kondisi ideal yang direncanakan di awal, misalnya kertas lembar OMR/ICR tidak sama dengan yang didesain dari awal baik dari sisi ukuran, bentuk maupun kondisinya. Penggunaan webform untuk operator yang kurang fasih menggunakan aplikasi webbased atau komputer juga akan menimbulkan kesulitan tersendiri dalam pengumpulan data.
STUDI KASUS
Berikut adalah contoh implementasi teknologi terkait yang pernah diimplementasikan oleh penulis dan pernah ditemui oleh penulis.
Koreksi Ujian Massal dalam waktu singkat
Sebuah organisasi meminta penulis mengkoreksi ujian sebanyak 116 ribu pelamar yang nilai nya harus diumumkan dalam waktu 1 hari setelah ujian. Penulis memilih teknologi Mark Reader dengan pertimbangan ujian tersebut menggunakan metode multiple choice atau pilihan ganda dan pertimbangan bahwa OMR membutuhkan verifikasi yang minimal dalam pelaksanaannya.
Penulis kemudian melakukan desain formulir yang pencetakannya diawasi secara ketat dari kualitas warna, ketebalan kertas, ukuran kertas dan teknik pemotongan kertas yang dicetak. Panitia ujian berkomitmen untuk melakukan sosialisasi cara mengisi lembar jawaban dengan tanda silang pada lembar OMR sebelum ujian dilakukan. Output laporannya pun disetujui di awal pelaksanaan sehingga sewaktu operasional tidak perlu lagi memikirkan bentuk data output.
Pada waktu pelaksanaan semua lembarjawab dikumpulkan kembali dan diatur rapi menurut warna masing – masing lembar jawaban oleh panitia, karena telah disepakati bahwa lembar berbeda memiliki kunci jawaban yang berbeda dan output setiap populasinya dipisahkan dengan populasi lainnya untuk mendapatkan statistik yang tepat untuk soal yang dibagaikan.
Tim dari penulis menggunakan 2 buah scanner, masing-masing kecepatan 100 lembar per menit dan 60 lembar per menit dengan software Mark Reader berkecepatan pembacaan 2500/menit dengan tim operasi 6 orang, 2 operator scanner dan 4 bertanggung jawab pada arus kertas.
Pekerjaan diselesaikan dalam waktu 6 jam dari pukul 10.00 malam hingga pukul 04.00 pagi dini hari dan diumumkan oleh panitia setelah melalui tahap cek ricek pada pukul 15.00.
Kunci pada implementasi OMR adalah perencanaan yang baik pada formulir, kemampuan operator, kapasitas scanner dan perencanaan output.
Teknologi Input Data dengan Flexible Layout OCR/ICR
Salah satu organisasi hendak menangkap data pada Invoice-Invoice yang dikirimkan oleh customer mereka dan kemudian diinput pada sistem yang online dengan bea cukai untuk pelaporan ekspor impor. Waktu untuk menginput data secara manual untuk satu invoice dengan jumlah 300 lembar dengan 3000 items adalah 4 hari kerja oleh 1 (satu) operator.
Penulis menyarankan implementasi Flexible Layout OCR dengan scanner ADF untuk mengotomatisasi data entry. Flexible Layout OCR adalah suatu aplikasi yang mampu menangkap data pada semi structured document yaitu dokumen yang mengandung informasi yang sama namun layout nya berbeda antara satu dokumen dengan dokumen lainnya. Keunggulan Flexible Layout OCR adalah perintah yang mudah kepada aplikasi untuk mencari data-data tertentu dengan tepat pada semi structured documents.
Penulis kemudian meminta sample beberapa jenis invoice dari customer yang berbeda (supaya aplikasi dapat menangkap lebar variasi dari letak data pada setiap invoice) , dari sampel tersebut dibuat suatu template untuk menangkap data pada dokumen-dokumen tersebut.
Pelaksanaan pada awalnya kurang lancar, dikarena dokumen yang diproses lebih bervariasi dari sampel yang diberikan sehingga diperlukan usaha tune-in template hingga tiga minggu untuk mencapai hasil yang maksimal. (maksimal = minimal verifikasi). Saat ini untuk memproses data invoice sebanyak 300 lembar dibutuhkan waktu selama 5 menit dengan akurasi tinggi.
Kunci pada implementasi Flexilayout OCR adalah sampel yang cukup mewakili pada saat mendesign template, kualitas image yang dihasilkan scanner, kemampuan operator mensetting scanner, kapasitas scanner, sosialisasi pengisian dan perencanaan output.
Data Entry dengan menggunakan ICR
Penulis membantu suatu organisasi untuk memproses aplikasi kartu kredit dengan tulisan tangan. Pada awalnya tim dari penulis menolak memproses aplikasi tersebut karena risiko yang besar akibat formulir tersebut sebenarnya tidak well designed untuk proses ICR sehingga penulis kuatir akan terlalu banyak verifikasi yang dilakukan. Namun setelah ada klarifikasi bahwa formulir baru akan dibuat berdasarkan usulan dari tim penulis maka implementasi ICR dapat disetujui.
Banyak kesalahpahaman bahwa teknologi ICR dapat membaca tulisan tangan orang dengan akurasi yang tinggi seberapa jeleknya pun tulisan orang tersebut. Perlu klarifikasi bahwa ICR tidak diciptakan untuk membaca tulisan tangan manusia yang jelek, ICR diciptakan untuk membaca tulisan tangan orang dalam range kualitas tertentu dimana satu huruf dapat dibedakan huruf lain dengan jelas, satu huruf terpisah dengan huruf lain dengan jelas dan satu huruf memiliki bentuk standar dengan penyimpangan yang minimal dari suatu standar. Itulah mengapa di aplikasi ICR dalam petunjuk pengisiannya ditulis : ditulis dengan huruf cetak. Jadi tidak tepat menggunakan ICR untuk membaca resep obat dokter misalnya.
Dalam implementasi ICR yang perlu diperhatikan adalah formulir harus memenuhi kaidah pembacaan ICR dengan risiko paling minimal, ketajaman hasil scanner, kemampuan operator, perlunya verifikasi intensif , validasi data dan pengumpulan output.
Saat ini sistem ICR di organisasi tersebut berjalan dengan produktivitas mencapai 3000 lembar/hari dengan 5 operator. (1 formulir ICR nya mencapai lebih dari 35 field).
Kunci dari implementasi ICR adalah persiapan lembar ICR yang rendah risiko, cetakan ICR berkualitas tinggi, kapasitas dan kualitas image scanner yang memadai, kecakapan operator ICR, sosialisasi pengisian dan perencanaan output yang baik.
Data Entry dengan menggunakan Barcode
Cara ini umum digunakan di pusat perbelanjaan, tracking logistik dan absensi karyawan. Yang menarik adalah penggunaan barcode untuk menyimpan 255 karakter seperti QR Code di Jepang dan beberapa implementasi di Indonesia.
Misalnya di pusat perbelanjaan buah-buahan, dimana timbangan/neraca disertai keyboard numeric , penimbang mengisi kode produk dan muncul stiker barcode dari printer kecil disebelah timbangan. Barcode tersebut mencatat nomor kode produk dan beratnya, sehingga ketika di scanning di mesin kasir, kode produk dan beratnya otomatis muncul dilayar.
Kunci dari implementasi Barcode adalah persiapan data base barcode, cetak barcode berkualitas dan aplikasi pengenal barcode yang mampu mendeteksi pada kondisi terdistorsi.
Sabtu, 18 April 2009
Berbagi dan berdiskusi mengenai teknologi scanner, kesenangan yang selalu berkembang, perburuan dari negara ke negara, tahun ke tahun.
Sejak memutuskan untuk mendirikan perusahaan yang khusus menangani scanner dan teknologinya berbagai permasalahan di lapangan muncul dan menuntut pengetahuan-pengetahuan tambahan yang praktis untuk mengatasi masalah tersebut. Mulai dari penciptaan trend “tanda silang” pada lembar jawab berbasis Digital Mark Reader pada psikotes, saya menyadari bahwa fitur-fitur scanner seperti border removal, color dropout dan thresholding menjadi penting dalam menjalankan berbagai tugas. Kami berdiskusi dengan para teknisi bahkan produsen scanner di dunia untuk menjawab berbagai masalah yang terjadi dalam pelaksanaan proyek.
Pendekatan yang kami lakukan pada customer , selalu didasarkan pada sukses implementasi dan memperkenalkan teknologi yang tepat untuk suatu proyek dokumentasi maupun recognition. Pada saat Digital Mark Reader, diciptakan oleh rekan kami ,Bapak Iping Supriyana dan Muh Arif Rahmat serta beberapa rekan lainnya , kecepatan proses hanya mencapai 8 lembar/menit dengan menggunakan scanner multifungsi HP 4110. Saat itu kami hanya berpikir mengenai pasar sekolah dan bersaingan dengan scanner OMR dengan positioning harga murah dan kompatibilitas penuh dengan windows. Sampai pada suatu saat kami bertemu dengan klien yang membutuhkan kecepatan lebih tinggi, kami mulai membuka diri untuk mencari scanner dokumen yang diperlukan untuk mencapai tujuan itu.
Pada tahun 2003 , kami mulai mendekati satu distributor scanner dan multifungsi terkemuka di indonesia, sayangnya saat itu kami ditertawakan oleh perusahaan tersebut karena kami hendak menggabungkan teknologi local Digital Mark Reader dengan scanner mahal, alhasil kami harus kembali dengan kekecewaan. Namun saat kami menghubungi PT Datascrip , kami disambut baik oleh manajer nya Ibu Aviantri Faiza dan Teknikal support Bapak Yordan , kami diperkenankan untuk mencoba teknologi scanner Canon. Setelah itu kami memperkenalkan produk Canon pada customer-customer DMR dengan embel-embel kata high speed (saat itu 20 lembar/menit, yang sekarang merupakan kecepatan bawah untuk scanner dokumen). Rekan-rekan kami dari Bandung berhasil menjual teknologi tersebut, kami di Jakarta malah jarang.
Sampai akhirnya ada seorang customer, hendak membeli scanner yang akan dipakai keesokan harinya untuk ujian dari Semarang. Kebetulan scanner Canon sedang habis stoknya, kami menghubungi PT Fujitsu Systems Indonesia dan dihandle oleh Bapak Andy Liem yang dengan telaten dan sabar melayani kami, beliau memberi banyak masukan mengenai aplikasi Digital Mark Reader. Proyek di semarang , kami menggunakan scanner fi 4220 dengan Digital Mark Reader. Saat itu kami menggunakan banyak scanner Fujitsu dibanding Canon , mengapa? Sederhana saja, dengan harga yang sama scanner Fujitsu memberikan kecepatan 25 ppm sedangkan Canon 20 ppm. Maklum saat itu kami masih belum melihat kecanggihan masing-masing scanner kecuali kecepatannya.

Gambar 1 : Memenangkan Award dari Fujitsu, kami mendapatkan Fujitsu Premium Partner Award 2006 dan Fujitsu Best Contibutor for Fi Scanners 2007
Waktu berjalan, tiba-tiba kami mendapat dukungan dari sebuah perusahaan untuk memproses CPNS 2004 dari suatu departemen sebanyak 2 juta lembar dalam waktu 10 hari. Untuk keperluan tersebut kami harus mencari scanner yang sanggup bersaing dengan kehandalan Mesin OMR. Kami terpikir menggunakan scanner Canon DR9080C dan scanner Fujitsu Fi 4860 dengan kecepatan masing-masing 90 lembar/menit dan 60 lembar/menit. Namun perusahaan yang hendak membawa kami, meminta jaminan bahwa scanner yang kami gunakan sanggup memproses puluhan hingga ratusan ribu lembar dalm sehari tanpa mengalami kerusakan atau panas. Tentunya kami meminta jaminan yang sama dari distributor scanner Fujitsu maupun Canon. Menunggu beberapa minggu, jaminan tersebut tidak ada karena para distributor terpaku pada angka Duty Cycle per day yang rendah dari setiap scanner. Brosur Fujitsu menyatakan kemampuan 10,000 lembar/hari serta Canon menyatakan 20,000 lembar/hari.
Akhirnya kami meng- “google” scanner unlimited duty cycle dan mendapatkan scanner Spectrum Bowe Bell & Howell seharga USD 38,000 fantastis! Kami mendapatkan scannernya, namun investasi untuk menebusnya tidak feasible. Sampai kemudian saya mendapatkan scanner panasonic kecepatan 25 ppm dan 45 ppm dengan duty cycle 4,500 per hari yang lebih handal dari tipe Fujitsu fi 4120 dan Canon 2080 dari sisi duty cycle. Kenapa kami sangat terobsesi dengan duty cycle ? Karena distributor scanner pihak lawan memanasi perusahaan yang hendak membawa kami, bahwa scanner dalam seharinya dilimit oleh duty cycle – seolah ada counter yang berjalan dalam 24 jam apabila dilewati, harus menunggu 24 jam selesai baru bisa melakukan scanning. Berhubung saat itu kami tidak tahu apa itu duty cycle scanner maka kami mengikuti arus mencari scanner duty cycle tinggi.

Gambar 2 : Scanner Spectrum Bowe Bell & Howell dengan spesifikasi unlimited duty cycle
Kami berhubungan dengan Alan Lim, sales manager dari Scientific Digital Business Singapore distributor dari Panasonic dan scanner Bowe Bell Howell. Kami langsung menuju Singapore melakukan testing scanner Bowe Bell Howell dan Panasonic. Dari diskusi pengalaman scanning dalam jumlah besar, kami diberitahu bahwa Duty Cycle adalah ukuran Mean Time Before Failure dari sebuah scanner dalam jangka waktu 5 tahun, artinya apabila kita ingin sebuah scanner dapat dipakai selama 5 tahun berapa lembar yang harus diproses dengan scanner. Duty cycle 1,000 lembar per hari artinya adalah apabila kita mengoperasikan scanner 1,000 lembar / hari dalam 5 tahun maka scanner dokumen itu kemungkinan akan habis masa pakainya. Kami kemudian berkenalan dengan sang pemilik SDB Wilson Chia, persahabatan dan jalinan bisnis ini berlangsung hingga saat ini. Pada proyek ini kami menggunakan scanner Bowe Bell Howell dan Scanner Panasonic dan sukses mencapai 2 juta lembar dalam 10 hari.


Gambar 5 : Diundang ke Bangkok mencoba scanner OMR Nanhao di Worldidac Asia , China saat ini merupakan produsen scanner OMR yang agresif
Pada tahun 2009 ini kami memegang beberapa merk scanner antara lain Fujitsu, Kodak, Canon, Miru, Avision, HP, Panasonic dan Bowe Bell and Howell dan kami selalu bertanya ke calon customer “Untuk apa “ dan “Kondisinya bagaimana” untuk memilihkan customer scanner mana yang tepat.

Pendekatan yang kami lakukan pada customer , selalu didasarkan pada sukses implementasi dan memperkenalkan teknologi yang tepat untuk suatu proyek dokumentasi maupun recognition. Pada saat Digital Mark Reader, diciptakan oleh rekan kami ,Bapak Iping Supriyana dan Muh Arif Rahmat serta beberapa rekan lainnya , kecepatan proses hanya mencapai 8 lembar/menit dengan menggunakan scanner multifungsi HP 4110. Saat itu kami hanya berpikir mengenai pasar sekolah dan bersaingan dengan scanner OMR dengan positioning harga murah dan kompatibilitas penuh dengan windows. Sampai pada suatu saat kami bertemu dengan klien yang membutuhkan kecepatan lebih tinggi, kami mulai membuka diri untuk mencari scanner dokumen yang diperlukan untuk mencapai tujuan itu.
Pada tahun 2003 , kami mulai mendekati satu distributor scanner dan multifungsi terkemuka di indonesia, sayangnya saat itu kami ditertawakan oleh perusahaan tersebut karena kami hendak menggabungkan teknologi local Digital Mark Reader dengan scanner mahal, alhasil kami harus kembali dengan kekecewaan. Namun saat kami menghubungi PT Datascrip , kami disambut baik oleh manajer nya Ibu Aviantri Faiza dan Teknikal support Bapak Yordan , kami diperkenankan untuk mencoba teknologi scanner Canon. Setelah itu kami memperkenalkan produk Canon pada customer-customer DMR dengan embel-embel kata high speed (saat itu 20 lembar/menit, yang sekarang merupakan kecepatan bawah untuk scanner dokumen). Rekan-rekan kami dari Bandung berhasil menjual teknologi tersebut, kami di Jakarta malah jarang.
Sampai akhirnya ada seorang customer, hendak membeli scanner yang akan dipakai keesokan harinya untuk ujian dari Semarang. Kebetulan scanner Canon sedang habis stoknya, kami menghubungi PT Fujitsu Systems Indonesia dan dihandle oleh Bapak Andy Liem yang dengan telaten dan sabar melayani kami, beliau memberi banyak masukan mengenai aplikasi Digital Mark Reader. Proyek di semarang , kami menggunakan scanner fi 4220 dengan Digital Mark Reader. Saat itu kami menggunakan banyak scanner Fujitsu dibanding Canon , mengapa? Sederhana saja, dengan harga yang sama scanner Fujitsu memberikan kecepatan 25 ppm sedangkan Canon 20 ppm. Maklum saat itu kami masih belum melihat kecanggihan masing-masing scanner kecuali kecepatannya.

Gambar 1 : Memenangkan Award dari Fujitsu, kami mendapatkan Fujitsu Premium Partner Award 2006 dan Fujitsu Best Contibutor for Fi Scanners 2007
Waktu berjalan, tiba-tiba kami mendapat dukungan dari sebuah perusahaan untuk memproses CPNS 2004 dari suatu departemen sebanyak 2 juta lembar dalam waktu 10 hari. Untuk keperluan tersebut kami harus mencari scanner yang sanggup bersaing dengan kehandalan Mesin OMR. Kami terpikir menggunakan scanner Canon DR9080C dan scanner Fujitsu Fi 4860 dengan kecepatan masing-masing 90 lembar/menit dan 60 lembar/menit. Namun perusahaan yang hendak membawa kami, meminta jaminan bahwa scanner yang kami gunakan sanggup memproses puluhan hingga ratusan ribu lembar dalm sehari tanpa mengalami kerusakan atau panas. Tentunya kami meminta jaminan yang sama dari distributor scanner Fujitsu maupun Canon. Menunggu beberapa minggu, jaminan tersebut tidak ada karena para distributor terpaku pada angka Duty Cycle per day yang rendah dari setiap scanner. Brosur Fujitsu menyatakan kemampuan 10,000 lembar/hari serta Canon menyatakan 20,000 lembar/hari.
Akhirnya kami meng- “google” scanner unlimited duty cycle dan mendapatkan scanner Spectrum Bowe Bell & Howell seharga USD 38,000 fantastis! Kami mendapatkan scannernya, namun investasi untuk menebusnya tidak feasible. Sampai kemudian saya mendapatkan scanner panasonic kecepatan 25 ppm dan 45 ppm dengan duty cycle 4,500 per hari yang lebih handal dari tipe Fujitsu fi 4120 dan Canon 2080 dari sisi duty cycle. Kenapa kami sangat terobsesi dengan duty cycle ? Karena distributor scanner pihak lawan memanasi perusahaan yang hendak membawa kami, bahwa scanner dalam seharinya dilimit oleh duty cycle – seolah ada counter yang berjalan dalam 24 jam apabila dilewati, harus menunggu 24 jam selesai baru bisa melakukan scanning. Berhubung saat itu kami tidak tahu apa itu duty cycle scanner maka kami mengikuti arus mencari scanner duty cycle tinggi.

Gambar 2 : Scanner Spectrum Bowe Bell & Howell dengan spesifikasi unlimited duty cycle
Kami berhubungan dengan Alan Lim, sales manager dari Scientific Digital Business Singapore distributor dari Panasonic dan scanner Bowe Bell Howell. Kami langsung menuju Singapore melakukan testing scanner Bowe Bell Howell dan Panasonic. Dari diskusi pengalaman scanning dalam jumlah besar, kami diberitahu bahwa Duty Cycle adalah ukuran Mean Time Before Failure dari sebuah scanner dalam jangka waktu 5 tahun, artinya apabila kita ingin sebuah scanner dapat dipakai selama 5 tahun berapa lembar yang harus diproses dengan scanner. Duty cycle 1,000 lembar per hari artinya adalah apabila kita mengoperasikan scanner 1,000 lembar / hari dalam 5 tahun maka scanner dokumen itu kemungkinan akan habis masa pakainya. Kami kemudian berkenalan dengan sang pemilik SDB Wilson Chia, persahabatan dan jalinan bisnis ini berlangsung hingga saat ini. Pada proyek ini kami menggunakan scanner Bowe Bell Howell dan Scanner Panasonic dan sukses mencapai 2 juta lembar dalam 10 hari.
Pada tahun 2004, Digital Mark Reader menjadi pilihan yang laris manis untuk mengolah ujian CPNS karena harga dan kemampuannya. Begitu banyaknya permintaan membuat kami mengorder segala scanner yang available, baik Canon, Panasonic maupun Fujitsu. Sementara di pasar psikotes kami memasang positioning produk yang lain daripada yang lain yaitu : satu-satunya Teknologi Mark Reader saat itu yang mampu membaca tanda silang tidak perlu diarsir penuh, sehingga para psikolog tidak perlu mengukur ulang waktu ujian kalau menggunakan sistem arsir penuh. Pengalaman dalam menangani berbagai merk dan type document scanner ini, membuat kami mengenal karakteristik dan sifat masing-masing scanner serta bagaimana menyikapi setiap implementasi scanner.

Gambar 3 : Kunjungan ke pabrik scanner Miru di Seoul Korea Selatan bersama president director miru dan distribution channel Miru
Waktu berjalan dan konsentrasi hanya pada bisnis document scanner dan Digital Mark Reader, membuat banyak organisasi dan perusahaan menghubungi kami untuk menangani berbagai macam proyek, hal ini semakin memperkaya pengetahuan kami dan kemampuan melayani customer yang semakin meningkat dari waktu ke waktu.
Gambar 4. Seminar ABBYY di St Petersburg Russia. Regional Director ABBYY untuk Asia Pacific Ms Eugeniya Izmesteva dan Head of Production Scanner Avision Mr Thomas Ng
Dari berbagai masalah yang timbul kami menyadari bahwa sebuah scanner yang merupakan scanner terbaik pada kasus tertentu, menjadi tidak performed pada kasus lain.
Sehingga apabila kita ditanya merk scanner yang paling baik, maka kita selalu bertanya lebih dahulu “untuk apa” dan “kondisi bagaimana”. Pada kondisi tertentu Fujitsu lebih baik dari Canon, pada kasus lain dapat terjadi sebaliknya, demikian pula dengan merk-merk lainnya, so “no scanner perfect in every situation”.

Gambar 5 : Diundang ke Bangkok mencoba scanner OMR Nanhao di Worldidac Asia , China saat ini merupakan produsen scanner OMR yang agresif
Pada tahun 2009 ini kami memegang beberapa merk scanner antara lain Fujitsu, Kodak, Canon, Miru, Avision, HP, Panasonic dan Bowe Bell and Howell dan kami selalu bertanya ke calon customer “Untuk apa “ dan “Kondisinya bagaimana” untuk memilihkan customer scanner mana yang tepat.

Gambar 6 : rekrutmen staff TransTV di Senayan, 116 ribu orang pelamar menjalani ujian, siapa yang dapat mengira bahwa untuk memproses selama 6 jam hanya membutuhkan 2 scanner dan 6 staff.
Kamis, 16 April 2009
Tips Scanning untuk menghadapi kertas Tipis dan Transparan untuk berbagai merk document scanner
Seringkali dalam melakukan scanning dokumen kita bertemu dokumen tipis (hampir transparan) dan bahkan kertas transparansi yang akan digitalisasi. Dengan setting scanner mode standar , hampir dipastikan image yang dihasilkan akan berwarna hitam legam atau timbul bayangan hitam yang merata. Pada tulisan ini akan dibahas setting advanced mode pada document scanner untuk produk Kodak, Fujitsu ,HP, dan Avision.
Pada contoh kali ini penulis menggunakan kertas HVS berukuran 55 gram cukup tipis dan transparan dengan menggunakan scanner Kodak scanmate i1220, Fujitsu Fi6130, HP Scanjet 7000, dan Avision 122.

Gambar 1: Hasil scanning menggunakan mode standar dan hasil scanning menggunakan advanced mode
Scanner Kodak
Untuk menangani scanning mode black and white (BW) pada scanner Kodak , pengguna scanner dapat melakukan setting sebagai berikut :
General : Pilih : Black and White, Document Type bebas, Media Type : Thin Paper.
Size : Border : Remove
Adjustment : Conversion Quality : Best (I thresholding : 0)

Gambar 2 : mode setting untuk kertas tipis nyaris transparan pada scanner Kodak
Scanner Fujitsu
Untuk menangani kertas transparan atau tipis pada scanner Fujitsu berikut setting yang dapat dilakukan :
Resolusi : 300 dpi, ScanType ADF[Frontside] (tergantung cara meletakkan kertas pada scanner), Papersize tergantung ukuran aktual kertas, Mode : BW, Black/White : Advanced DTC.

Gambar 3 : mode setting untuk kertas tipis nyaris transparan pada scanner Fujitsu
Scanner HP
Untuk menangani kertas transparan atau tipis pada scanner HP berikut setting yang dapat dilakukan oleh operator:
Main : Mode (Black and White), Dots per inch (300 dpi), Threshold (96-128).
Perhatikan bahwa semakin kecil threshold maka semakin tampak bayangan hitam, sebaliknya semakin besar threshold maka beberapa informasi tulisan bisa semakin kabur.
Diperlukan adjustment yang bisa dilakukan melalui mekanisme preview.

Gambar 4 : Mode setting scanner pada Scanner HP Scanjet 7000
Scanner Avision
Untuk scanner Avision, berikut setting yang dapat diterapkan oleh operator :
Image Binarization : Dynamic Threshold
Option : Edge Fill White = 2mm,Whitebackground

Gambar 5 : Mode setting scanner pada Scanner Avision
Demikian semoga tulisan ini dapat membantu yang mengalami kesulitan menghadapi kertas tipis dan transparan.
Pada contoh kali ini penulis menggunakan kertas HVS berukuran 55 gram cukup tipis dan transparan dengan menggunakan scanner Kodak scanmate i1220, Fujitsu Fi6130, HP Scanjet 7000, dan Avision 122.

Gambar 1: Hasil scanning menggunakan mode standar dan hasil scanning menggunakan advanced mode
Scanner Kodak
Untuk menangani scanning mode black and white (BW) pada scanner Kodak , pengguna scanner dapat melakukan setting sebagai berikut :
General : Pilih : Black and White, Document Type bebas, Media Type : Thin Paper.
Size : Border : Remove
Adjustment : Conversion Quality : Best (I thresholding : 0)

Gambar 2 : mode setting untuk kertas tipis nyaris transparan pada scanner Kodak
Scanner Fujitsu
Untuk menangani kertas transparan atau tipis pada scanner Fujitsu berikut setting yang dapat dilakukan :
Resolusi : 300 dpi, ScanType ADF[Frontside] (tergantung cara meletakkan kertas pada scanner), Papersize tergantung ukuran aktual kertas, Mode : BW, Black/White : Advanced DTC.

Gambar 3 : mode setting untuk kertas tipis nyaris transparan pada scanner Fujitsu
Scanner HP
Untuk menangani kertas transparan atau tipis pada scanner HP berikut setting yang dapat dilakukan oleh operator:
Main : Mode (Black and White), Dots per inch (300 dpi), Threshold (96-128).
Perhatikan bahwa semakin kecil threshold maka semakin tampak bayangan hitam, sebaliknya semakin besar threshold maka beberapa informasi tulisan bisa semakin kabur.
Diperlukan adjustment yang bisa dilakukan melalui mekanisme preview.

Gambar 4 : Mode setting scanner pada Scanner HP Scanjet 7000
Scanner Avision
Untuk scanner Avision, berikut setting yang dapat diterapkan oleh operator :
Image Binarization : Dynamic Threshold
Option : Edge Fill White = 2mm,Whitebackground

Gambar 5 : Mode setting scanner pada Scanner Avision
Demikian semoga tulisan ini dapat membantu yang mengalami kesulitan menghadapi kertas tipis dan transparan.
Selasa, 14 April 2009
Berhitung Produktivitas ICR (Intelligent Character Recognition) dengan mempertimbangkan risiko – risiko implementasi yang akan terjadi
Teknologi ICR (intelligent character recognition) secara umum disebut sebagai teknologi pengenal karakter yang umumnya berupa alfanumeris (huruf, angka dan tanda baca) dari satu atau sekumpulan image digital. Aplikasi ini umum dipergunakan pada data entry dalam jumlah besar dengan menggunakan scanner dokumen. Teknologi ini di Indonesia telah umum digunakan untuk data entry, riset pasar, penerimaan pegawai, dan saat ini digunakan untuk memproses data pemilu Indonesia 2009 (teknologi ICR pada pemilu 2009 lebih tepat disebut numerical character recognition, karena hanya angka yang dikenali).
Bagaimana mengukur produktivitas atau efektivitas ICR ? Banyak metode estimasi kecepatan proses ICR yang dilakukan oleh para implementor ICR. Ada yang dengan mudah menghitung berdasarkan kecepatan scanner dengan anggapan bahwa semakin tinggi kecepatan scanner maka semakin tinggi produktivitas ICR. Ada yang menghitung berdasarkan tingkat akurasi pembacaan. Ada yang menggunakan asumsi kemudahan verifikasi dan lain sebagainya.
Dalam tulisan ini penulis sekedar memberikan pendapat mengenai faktor-faktor yang perlu diperhitungkan dalam implementasi ICR, yang diperoleh penulis dari pengalamannya menangani beberapa proyek ICR yang telah diimplementasikan di Indonesia. Tulisan ini bukan berarti merupakan generalisasi yang bisa diterapkan pada setiap situasi. Penulis mencoba menelusuri faktor kritikal yang mendukung efektivitas ICR melalui proses yang terjadi dari sejak melakukan desain formulir ICR, pencetakan formulir ICR, sosialisasi pengisian, scanning, operasi aplikasi ICR dan support dari penyedia Teknologi.
Desain Formulir ICR
Dalam mendesain formulir ICR perlu diingat bahwa formulir ICR ini akan diproses oleh komputer sehingga desain formulir ICR haruslah memperhitungkan keunggulan dan kelemahan teknologi yang akan dipergunakan bukan hanya mempertimbangkan kemudahan pengisian oleh responden.
Anchor Object Statis
Untuk memproses formulir ICR yang biasanya seragam , aplikasi ICR memetakan letak field pada dokumen pada jarak tertentu berpatokan pada anchor object statis. Anchor object statis ini dapat berupa kotak hitam sejumlah 4 atau lebih , atau dapat berupa teks statis yang muncul pada setiap dokumen dan posisinya tetap. Tujuan dari anchor ini adalah agar ICR dapat mengenali dengan tepat lokasi dimana field berada tanpa terganggu oleh distorsi pada percetakan, misalnya potongan kertas yang berbeda-beda atau pun rotasi-rotasi ringan akibat salah setting pada mesin cetak.

Gambar 1 : Berbagai jenis anchor object statis , perhatikan bujursangkar hitam pekat pada ujung –ujung formulir ICR adalah statis anchor yang digunakan untuk menentukan letak field-field.
Dalam ini perlu dipahami bahwa apabila dalam proses cetak terjadi kesalahan, sehingga anchor object statis cacat atau hilang maka formulir ini otomatis tidak dapat dikenali oleh ICR dan diperlukan template pembacaan atau pemetaan field ICR yang baru. Ibarat bagaimana dahulu teman kos saya di Sunter hendak pulang ke ciledug mengendarai sepeda motor, ia selalu harus menemukan Monas terlebih dahulu. Setelah dari monas , ia dapat mengetahui jalan mana yang menuju ke Ciledug.Apabila Monas tiba-tiba hilang maka besar kemungkinan ia tidak bisa pulang ke Ciledug. Disini Monas adalah anchor object statis baginya untuk menemukan Ciledug.
Anchor Object Dinamis
Beberapa aplikasi form processing termutakhir juga memiliki anchor object dinamis. Anchor object dinamis adalah anchor object untuk menangani field-field yang letaknya tidak seragam pada formulir ICR. Anchor object dinamis dapat berupa kotak hitam, garis maupun teks. Anchor object dinamis diibaratkan seseorang mencari pedagang es campur di pasar yang selalu berdagang berdekatan dengan truk warna merah dengan nomor polisi B7777XC. Untuk mencari pedagang ini, kita harus terlebih dahulu letak pasarnya, kemudian kita harus menemukan truk warna merah dengan nomor polisi B7777XC dan kemudian mencari objek didekatnya yang berjualan es. Dalam hal ini truk warna merah adalah anchor object dinamis bagi sang pedagang es. Keunggulan sistem ini adalah selama lokasinya tetap di pasar dan pedagang es itu konsisten untuk berjualan es di dekat truk merah B7777XC maka ia akan tetap dengan mudah ditemukan meskipun ia berdagang berpindah-pindah disekitar pasar (dengan tentunya truk merah B7777XC tersebut ikut berpindah-pindah).

Gambar 2. Implementasi anchor object dinamis, perhatikan bahwa field nama selalu dapat ditemukan meski bentuk formulir berbeda satu sama lain. Teknik yang digunakan adalah menggunakan text “Nama Peserta’ atau “Nama Lengkap” sebagai anchor object dinamis. Disini penulis memberikan referensi bahwa field “nama” letaknya selalu disebelah kanan dari anchor object dinamis.
Aplikasi anchor object dinamis banyak digunakan pada aplikasi scanner kartu nama, dimana nama , alamat, nomor telpon dan email dapat langsung dikenali dan dimasukkan pada field yang benar.
2. Marking Type
Untuk memudahkan separasi antara satu huruf dengan huruf lainnya ,biasanya disediakan tempat menulis huruf per huruf bagi responden yang mengisi formulir ICR, bentuk dari tempat menulis ini disebut sebagai marking type. Jenis marking type yang dipilih akan mempengaruhi tingkat keberhasilan pembacaan ICR.

Gambar 3 Jenis-jenis marking type yang umum digunakan pada teknologi ICR
Marking type yang memiliki risiko kegagalan separasi yang tinggi adalah marking type yang tidak membatasi tinggi huruf dan jarak antar hurufnya sehingga risiko huruf satu menempel pada huruf lainnya sangat besar. Marking type yang memiliki risiko kegagalan yang terendah adalah marking type yang membatasi tinggi huruf dan jarak antar huruf sehingga dapat dipisahkan huruf per huruf dengan jelas disertai tingkat gangguan yang
rendah.

Gambar 4. Marking Type kotak dengan warna hitam akan hasil yang akurat pada kondisi image dimana marking typenya terlihat tajam dengan jarak yang konsisten. Namun apabila image yang dihasilkan mengalami distorsi atau template tidak didesain dengan marking type yang benar maka garis vertikal yang ada akan terbaca sebagai huruf “I” atau angka “1” Contoh “KOTA PINANG” dapat terbaca sebagai “KIOITAI IPIINIAINIG” dalam hal ini hasil ICR dapat terganggu oleh garis vertikal marking type.
Tingkat gangguan yang dimaksud antara lain adaya garis-garis pemisah atau kotak-kotak pada marking type dapat terbaca sebagai huruf I atau karakter lain pada kondisi scanning yang terdistorsi.

Gambar 5 Teknik Color dropout , pada formulir ICR terkotak-kotak dengan marking type berwarna merah, gambar disebelahnya adalah hasil scanning color dropout, perhatikan bahwa gangguan berupa garis vertikal marking type tidak muncul sehingga pembacaan lebih terjamin akurasinya.
Kondisi terbaik adalah menggunakan taktik color dropout atau raster form. Color dropout marking type adalah kondisi dimana formulir ICR memiliki marking type dengan warna yang dapat di drop out (dihilangkan) oleh scanner sehingga separasinya tetap terjaga (karena huruf dibatasi kotak-kotak berwarna) dan gangguannya minimal (karena waktu scan kotak-kotak ini dihilangkan dengan color dropout). Sedangkan pada taktik raster form garis-garis atau kotak-kotak pada marking type diganti dengan titik-titik dengan jarak tertentu yang membentuk garis atau kotak, pada saat scanning titik-titik ini akan dihilangkan oleh fitur despeckle atau noise removal pada scanner.

Gambar6 Teknik raster, gambar atas adalah formulir ICR yang dipergunakan dengan menggunakan raster berupa titik-titik yang membentuk kotak marking type, gambar bawah adalah hasil scanning menggunakan fitur scanner noise removal atau despeckle. Disini separasi antar huruf sangat jelas dan gangguan pembacaan tidak ada.
Pembatasan bentuk huruf (misal hanya boleh kapital) akan meningkatkan akurasi dari ICR.
Pencetakan Lembar Formulir ICR
Apabila semua hal diatas sudah terdesain dengan baik maka percetakan adalah hal kritikal dalam proses persiapan formulir ICR. Untuk penggunaan anchor object statis dan dinamis perlu diperiksa apakah anchor object itu masih tampak jelas pada hasil cetak (ingat teman saya yang kehilangan Monas). Untuk penggunaan marking type warna hitam perlu dipastikan garis-garis atau kotak yang ada memiliki jarak yang seragam dan tingkat kehitaman yang pekat. Untuk taktik color drop out perlu dipastikan warna yang digunakan dapat didropout oleh scanner dan jarak antara anchor object yang berwarna hitam dengan field warna tidak bergeser atau bahkan berotasi. Untuk taktik raster perlu di pastikan bahwa dot raster memiliki warna yang soft dengan ukuran kecil sehingga dapat dideteksi sebagai noise dan dapat dihilangkan oleh scanner
Sosialisasi Pengisian Formulir ICR
Selain dari petunjuk pengisian yang jelas pada formulir ICR , diperlukan pula sosialisasi pengisian formulir sehingga data yang didapatkan dapat dikenali oleh ICR dan juga letak field maupun bentuk datanya sesuai dengan yang kita inginkan. Tanpa sosialisasi yang jelas , seringkali data yang kita dapatkan berbeda dengan yang kita inginkan , misalkan kita ingin responden mengisi kode kota dengan angka pada 3 kotak, namun yang kita dapatkan adalah nama kota dalam singkatan tiga huruf.
Cara penulisan pada formulir ICR juga dapat dijelaskan pada forum sosialisasi sehingga tulisan-tulisan yang tidak mengikuti kaidah ICR dalam mengisi formulir ICR dapat dihindari atau direduksi.
Teknik Scanning
Teknik scanning tidak melulu melibatkan kecepatan scanning namun juga metode scanning dan hasil scanning yang ingin didapatkan.
Batch scanning
Batch adalah sekelompok dokumen yang dapat discan sebagai satu kesatuan kelompok data atau satuan pemisahan image hasil scan. Pada aplikasi ICR untuk kartu kredit misalnya , satu batch dapat mewakili sejumlah data customer pada suatu waktu (misalnya hari) dan ditempatkan pada folder dengan nama sesuai jenis aplikasi dan tanggal aplikasi formulir ICR discan. Apabila dalam satu batch terdiri dari lebih dari 50 lembar maka scanner ADF akan bekerja cukup optimal karena cukup menumpuk 50 kertas ke dalam papertray dan menjalankan scanning maka scanner akan memproduksi image secara otomatis satu persatu dengan kecepatan tinggi.
Pada kondisi tertentu pengelompokan image hanya boleh dilakukan sedikit demi sedikit misalkan 10 lembar dan kemudian ditempatkan pada folder tertentu dan kemudian baru boleh memproses batch berikutnya, dalam hal ini scanner tidak akan bekerja optimal karena menunggu interaksi dari operator untuk berpindah-pindah folder. Pada kondisi ini scanner ADF kecepatan 30 ppm maupun 60 ppm tidak banyak berpengaruh pada produktivitas ICR.
Strategi penggunaan batch scanning dengan separator dapat mempercepat kondisi diatas apabila memungkinkan(beberapa aplikasi ICR mendukung batch separator). Batch separator adalah teknik scanning dengan menumpuk antar kelompok dokumen dengan memberikan lembar pemisah atau separator berupa patchcode atau barcode sehingga aplikasi batch scanning membuat folder terpisah secara otomatis setiap kali menemukan separator.
Metode scanning
Kembali pada strategi awal desain
Metode scanning berkaitan dengan strategi awal dalam membuat formulir ICR. Apabila strategi awal menggunakan anchor statis berwarna hitam dengan marking type hitam maka perlu dicari setting scanner yang dapat menghasilkan anchor yang sejelas mungkin dan marking type yang sejelas mungkin. Apabila metode scanning menggunakan color dropout maka perlu diyakinkan bahwa setting scanner mengadopsi color dropout yang sesuai dengan warna formulir ICR dan image yang dihasilkan field yang bersih dari marking type yang tadinya berwarna. Bila metode scanning menggunakan raster maka perlu diaktifkan setting noise removal atau despeckle untuk menghilang titik-titik pada marking type.
Menghilangkan gangguan akibat ukuran kertas yang berbeda-beda
Biasanya beberapa scanner ADF menghasilkan image yang tepinya berwarna hitam apabila ukuran kertas yang didefinisikan pada setting scanner lebih besar dari kertas formulir ICR. Untuk mengatasi hal ini, scanner menyediakan beberapa setting opsi antara lain border removal (menghilangkan bingkai warna hitam yang terjadi pada tepi image), white background (memberikan background putih pada tepi image) , X-Y cropping (memotong gambar dari tepi atas maupun samping) , dan automatic page detection (yaitu otomatis melakukan cropping sesuai ukuran kertas).
Menghilangkan gangguan akibat tipisnya kertas
Kertas tipis seringkali menyebabkan image yang dihasilkan terganggu oleh bayangan lampu scanner, dan muncul sekelompok warna hitam atau abu-abu yang dapat mengganggu pembacaan ICR. Pada scanner tertentu hal ini dapat diatasi dengan mode whitebackground serta penggunaan mode advanced thresholding .
Mengaktifkan Multifeed detection dan waspada terhadap paperjam
Kelemahan scanner ADF pada umumnya adalah menarik kertas lebih dari satu dan juga paperjam atau kertas macet pada scanner. Multifeed detection adalah fitur scanner yang mampu mendeteksi halaman lebih dari satu yang ditarik oleh mekanisme ADF dan secara otomatis menghentikan proses scanning apabila terjadi penarikan ganda.
Pada kondisi paperjam yang perlu diwaspadai adalah penciptaan image berulang pada lembar yang sama oleh aplikasi scanner. Apabila terjadi image berulang , dapat dilakukan penghapusan gambar dan baru mengulang scanning.
Pada tahap ini aplikasi ICR mulai memproses dan mengenali image hasil dari scanning menjadi teks. Faktor yang mempengaruhi kecepatan operator adalah :
1. Kemampuan operator
2. Kemudahan mengoperasikan ICR
3. Tingkat akurasi recognition dan kecepatan recognition
4. Metode operasi ICR
5. Metode verifikasi
6. Metode validasi
7. Kemudahan mengekspor menjadi hasil yang dikehendaki
1.Kemampuan operator
Kemampuan dan pemahaman operator merupakan kunci sukses dari implementasi ICR. Teknologi ini masih dioperasikan oleh manusia sehingga kelancaran proses dan data yang dihasilkan benar-benar sangat tergantung pada operatornya. Pelatihan yang intensif dan serius serta materi pelatihan yang mengarah pada praktek sangat diharapkan untuk dilakukan pada saat pre-implementasi. Selain itu sikap mental yang mau belajar, teliti serta bertanggungjawab merupakan modal utama menjadi operator ICR yang handal.
2.Kemudahan mengoperasikan ICR
Desain antar muka yang mudah dipahami dan dipelajari menjadi kekuatan aplikasi ICR untuk meningkatkan pemahaman dan berujung pada peningkatan produktivitas dari teknologi ICR. Penting menyembunyikan fitur-fitur dahsyat ICR ke dalam ruang lingkup administrator dan menyerahkan tugas yang mudah ke lingkup operator sehingga kerumitan-kerumitan aplikasi tidak dialami oleh operator.
3.Tingkat akurasi ICR dan kecepatan recognition
Tingkat akurasi dan kecepatan recognition menjadi salah satu faktor penentu kecepatan operasi dengan ICR, dimana akurasi yang baik akan mengurangi jumlah verifikasi yang dilakukan operator (untuk beberapa kasus hal ini benar, pada kasus yang berbeda hal ini menjadi tidak relevan dengan catatan akurasinya masih dicapai angka minimal 70-75%). Kata tingkat akurasi ini menjadi sangat relatif dan tergantung banyak hal terutama faktor yang sebelumnya sudah dibahas yaitu desain awal formulir ICR, kualitas cetak, kualitas scanning serta kualitas tulisan yang mengisi formulir ICR (sudah disosialisasikan cara pengisiannya atau belum) selain metode recognitionnya sendiri.
Apabila diinginkan hasil yang akurat 100% maka semua field yang sudah dikenali oleh ICR harus 100% diverifikasi ulang oleh operator. Proses ini akan memakan waktu cukup lama dan akurasi 80% dengan 90% kemungkinan menjadi kurang relevan untuk menghitung produktivitas ICR pada kondisi ini. Mengapa harus diverifikasi ulang 100% oleh operator dan bukannya yang diragukan saja yang diverifikasi oleh operator ? Dikarenakan tingkat keyakinan baca pada ICR mengandung apa yang dinamakan false positive atau hidden error , sering terjadi ICR yakin dengan yang dibacanya angka “4”, ternyata oleh mata manusia dinyatakan dengan pasti sebagai angka “9”.

Gambar 7. False Positive : dimana yang dimaksudkan adalah KUSUMA namun ICR dengan pasti menebak KUSVMA sehingga tidak muncul di panel verifikasi apabila tidak dilakukan mode full verification.
4.Metode Operasi ICR
Metode operasi ICR biasanya ada dua macam yaitu stand alone dan kolaboratif. Pada sistem stand alone seorang operator melakukan semua proses dari scanning, recognition, verification, validation dan ekspor hasil sehingga semua alur proses akan bergantung pada sebuah komputer dan operatornya. Pada sistem kolaboratif sistem ICR membagi fungsi scanning, recognition, verification , validation dan ekspor pada beberapa operator dan komputer yang berbeda.
Metode standalone dapat digunakan pada suatu sistem yang memperbolehkan data tersebar prosesnya pada beberapa komputer dan hasil yang diharapkan juga terpisah-pisah pada lokasi yang berbeda. Metode ini juga cocok untuk melakukan proses data yang tidak begitu banyak. Kerugian pada sistem ini adalah penggunaan scanner yang tidak efisien, bottleneck pada satu komputer dan konsentrasi operator yang tinggi dalam menangani semua proses.
7.Kemudahan melakukan ekspor menjadi data yang dikehendaki
Untuk menangani hal ini diperlukan sistem support yang memadai dan mudah, misalnya dengan secara sederhana mengirimkan hasil scanning pada support untuk kemudian ditindaklanjuti dengan membalas email solusinya atau desain template yang cocok untuk menghadapi situasi yang dihadapi. Kelambatan dan ketiadaan support menimbulkan kelambatan proses ICR yang tidak terukur.
Perhitungan Risiko pada Teknologi ICR dan Pengaruhnya Pada Keberhasilan dan waktu Prosesnya.

Dengan beberapa faktor diatas maka penulis mencoba melakukan tabulasi risiko dan pengaruhnya terhadap produktivitas sistem ICR
Demikian sekiranya beberapa faktor utama yang menurut penulis mempengaruhi waktu proses dari suatu teknologi ICR, sebatas pengetahuan penulis. Faktor – faktor ini kiranya dapat diperhitungkan dalam melakukan estimasi proses ICR dan dapat dipertimbangkan sebagai suatu tahapan kritikal yang harus dipertimbangkan dalam implementasi penggunaan ICR pada suatu proses data entry. Tentunya banyak hal-hal lain yang dapat mempengaruhi waktu proses maupun tingkat keberhasilan dalam implementasi yang luput dari perhatian penulis yang diharapkan dapat menjadi masukan untuk menyempurnakan pengetahuan penulis yang terbatas berdasarkan pengalaman di beberapa proyek di Indonesia.
Bagaimana mengukur produktivitas atau efektivitas ICR ? Banyak metode estimasi kecepatan proses ICR yang dilakukan oleh para implementor ICR. Ada yang dengan mudah menghitung berdasarkan kecepatan scanner dengan anggapan bahwa semakin tinggi kecepatan scanner maka semakin tinggi produktivitas ICR. Ada yang menghitung berdasarkan tingkat akurasi pembacaan. Ada yang menggunakan asumsi kemudahan verifikasi dan lain sebagainya.
Dalam tulisan ini penulis sekedar memberikan pendapat mengenai faktor-faktor yang perlu diperhitungkan dalam implementasi ICR, yang diperoleh penulis dari pengalamannya menangani beberapa proyek ICR yang telah diimplementasikan di Indonesia. Tulisan ini bukan berarti merupakan generalisasi yang bisa diterapkan pada setiap situasi. Penulis mencoba menelusuri faktor kritikal yang mendukung efektivitas ICR melalui proses yang terjadi dari sejak melakukan desain formulir ICR, pencetakan formulir ICR, sosialisasi pengisian, scanning, operasi aplikasi ICR dan support dari penyedia Teknologi.
Desain Formulir ICR
Dalam mendesain formulir ICR perlu diingat bahwa formulir ICR ini akan diproses oleh komputer sehingga desain formulir ICR haruslah memperhitungkan keunggulan dan kelemahan teknologi yang akan dipergunakan bukan hanya mempertimbangkan kemudahan pengisian oleh responden.
1. Anchor Object
Anchor Object Statis
Untuk memproses formulir ICR yang biasanya seragam , aplikasi ICR memetakan letak field pada dokumen pada jarak tertentu berpatokan pada anchor object statis. Anchor object statis ini dapat berupa kotak hitam sejumlah 4 atau lebih , atau dapat berupa teks statis yang muncul pada setiap dokumen dan posisinya tetap. Tujuan dari anchor ini adalah agar ICR dapat mengenali dengan tepat lokasi dimana field berada tanpa terganggu oleh distorsi pada percetakan, misalnya potongan kertas yang berbeda-beda atau pun rotasi-rotasi ringan akibat salah setting pada mesin cetak.
Gambar 1 : Berbagai jenis anchor object statis , perhatikan bujursangkar hitam pekat pada ujung –ujung formulir ICR adalah statis anchor yang digunakan untuk menentukan letak field-field.
Dalam ini perlu dipahami bahwa apabila dalam proses cetak terjadi kesalahan, sehingga anchor object statis cacat atau hilang maka formulir ini otomatis tidak dapat dikenali oleh ICR dan diperlukan template pembacaan atau pemetaan field ICR yang baru. Ibarat bagaimana dahulu teman kos saya di Sunter hendak pulang ke ciledug mengendarai sepeda motor, ia selalu harus menemukan Monas terlebih dahulu. Setelah dari monas , ia dapat mengetahui jalan mana yang menuju ke Ciledug.Apabila Monas tiba-tiba hilang maka besar kemungkinan ia tidak bisa pulang ke Ciledug. Disini Monas adalah anchor object statis baginya untuk menemukan Ciledug.
Anchor Object Dinamis
Beberapa aplikasi form processing termutakhir juga memiliki anchor object dinamis. Anchor object dinamis adalah anchor object untuk menangani field-field yang letaknya tidak seragam pada formulir ICR. Anchor object dinamis dapat berupa kotak hitam, garis maupun teks. Anchor object dinamis diibaratkan seseorang mencari pedagang es campur di pasar yang selalu berdagang berdekatan dengan truk warna merah dengan nomor polisi B7777XC. Untuk mencari pedagang ini, kita harus terlebih dahulu letak pasarnya, kemudian kita harus menemukan truk warna merah dengan nomor polisi B7777XC dan kemudian mencari objek didekatnya yang berjualan es. Dalam hal ini truk warna merah adalah anchor object dinamis bagi sang pedagang es. Keunggulan sistem ini adalah selama lokasinya tetap di pasar dan pedagang es itu konsisten untuk berjualan es di dekat truk merah B7777XC maka ia akan tetap dengan mudah ditemukan meskipun ia berdagang berpindah-pindah disekitar pasar (dengan tentunya truk merah B7777XC tersebut ikut berpindah-pindah).

Gambar 2. Implementasi anchor object dinamis, perhatikan bahwa field nama selalu dapat ditemukan meski bentuk formulir berbeda satu sama lain. Teknik yang digunakan adalah menggunakan text “Nama Peserta’ atau “Nama Lengkap” sebagai anchor object dinamis. Disini penulis memberikan referensi bahwa field “nama” letaknya selalu disebelah kanan dari anchor object dinamis.
Aplikasi anchor object dinamis banyak digunakan pada aplikasi scanner kartu nama, dimana nama , alamat, nomor telpon dan email dapat langsung dikenali dan dimasukkan pada field yang benar.
2. Marking Type
Untuk memudahkan separasi antara satu huruf dengan huruf lainnya ,biasanya disediakan tempat menulis huruf per huruf bagi responden yang mengisi formulir ICR, bentuk dari tempat menulis ini disebut sebagai marking type. Jenis marking type yang dipilih akan mempengaruhi tingkat keberhasilan pembacaan ICR.

Gambar 3 Jenis-jenis marking type yang umum digunakan pada teknologi ICR
Marking type yang memiliki risiko kegagalan separasi yang tinggi adalah marking type yang tidak membatasi tinggi huruf dan jarak antar hurufnya sehingga risiko huruf satu menempel pada huruf lainnya sangat besar. Marking type yang memiliki risiko kegagalan yang terendah adalah marking type yang membatasi tinggi huruf dan jarak antar huruf sehingga dapat dipisahkan huruf per huruf dengan jelas disertai tingkat gangguan yang
rendah.

Gambar 4. Marking Type kotak dengan warna hitam akan hasil yang akurat pada kondisi image dimana marking typenya terlihat tajam dengan jarak yang konsisten. Namun apabila image yang dihasilkan mengalami distorsi atau template tidak didesain dengan marking type yang benar maka garis vertikal yang ada akan terbaca sebagai huruf “I” atau angka “1” Contoh “KOTA PINANG” dapat terbaca sebagai “KIOITAI IPIINIAINIG” dalam hal ini hasil ICR dapat terganggu oleh garis vertikal marking type.
Tingkat gangguan yang dimaksud antara lain adaya garis-garis pemisah atau kotak-kotak pada marking type dapat terbaca sebagai huruf I atau karakter lain pada kondisi scanning yang terdistorsi.

Gambar 5 Teknik Color dropout , pada formulir ICR terkotak-kotak dengan marking type berwarna merah, gambar disebelahnya adalah hasil scanning color dropout, perhatikan bahwa gangguan berupa garis vertikal marking type tidak muncul sehingga pembacaan lebih terjamin akurasinya.
Kondisi terbaik adalah menggunakan taktik color dropout atau raster form. Color dropout marking type adalah kondisi dimana formulir ICR memiliki marking type dengan warna yang dapat di drop out (dihilangkan) oleh scanner sehingga separasinya tetap terjaga (karena huruf dibatasi kotak-kotak berwarna) dan gangguannya minimal (karena waktu scan kotak-kotak ini dihilangkan dengan color dropout). Sedangkan pada taktik raster form garis-garis atau kotak-kotak pada marking type diganti dengan titik-titik dengan jarak tertentu yang membentuk garis atau kotak, pada saat scanning titik-titik ini akan dihilangkan oleh fitur despeckle atau noise removal pada scanner.

Gambar6 Teknik raster, gambar atas adalah formulir ICR yang dipergunakan dengan menggunakan raster berupa titik-titik yang membentuk kotak marking type, gambar bawah adalah hasil scanning menggunakan fitur scanner noise removal atau despeckle. Disini separasi antar huruf sangat jelas dan gangguan pembacaan tidak ada.
3. Ukuran Huruf dan Jenis Data
Pembatasan bentuk huruf (misal hanya boleh kapital) akan meningkatkan akurasi dari ICR.
Pencetakan Lembar Formulir ICR
Apabila semua hal diatas sudah terdesain dengan baik maka percetakan adalah hal kritikal dalam proses persiapan formulir ICR. Untuk penggunaan anchor object statis dan dinamis perlu diperiksa apakah anchor object itu masih tampak jelas pada hasil cetak (ingat teman saya yang kehilangan Monas). Untuk penggunaan marking type warna hitam perlu dipastikan garis-garis atau kotak yang ada memiliki jarak yang seragam dan tingkat kehitaman yang pekat. Untuk taktik color drop out perlu dipastikan warna yang digunakan dapat didropout oleh scanner dan jarak antara anchor object yang berwarna hitam dengan field warna tidak bergeser atau bahkan berotasi. Untuk taktik raster perlu di pastikan bahwa dot raster memiliki warna yang soft dengan ukuran kecil sehingga dapat dideteksi sebagai noise dan dapat dihilangkan oleh scanner
Sosialisasi Pengisian Formulir ICR
Selain dari petunjuk pengisian yang jelas pada formulir ICR , diperlukan pula sosialisasi pengisian formulir sehingga data yang didapatkan dapat dikenali oleh ICR dan juga letak field maupun bentuk datanya sesuai dengan yang kita inginkan. Tanpa sosialisasi yang jelas , seringkali data yang kita dapatkan berbeda dengan yang kita inginkan , misalkan kita ingin responden mengisi kode kota dengan angka pada 3 kotak, namun yang kita dapatkan adalah nama kota dalam singkatan tiga huruf.
Cara penulisan pada formulir ICR juga dapat dijelaskan pada forum sosialisasi sehingga tulisan-tulisan yang tidak mengikuti kaidah ICR dalam mengisi formulir ICR dapat dihindari atau direduksi.
Teknik Scanning
Teknik scanning tidak melulu melibatkan kecepatan scanning namun juga metode scanning dan hasil scanning yang ingin didapatkan.
Batch scanning
Batch adalah sekelompok dokumen yang dapat discan sebagai satu kesatuan kelompok data atau satuan pemisahan image hasil scan. Pada aplikasi ICR untuk kartu kredit misalnya , satu batch dapat mewakili sejumlah data customer pada suatu waktu (misalnya hari) dan ditempatkan pada folder dengan nama sesuai jenis aplikasi dan tanggal aplikasi formulir ICR discan. Apabila dalam satu batch terdiri dari lebih dari 50 lembar maka scanner ADF akan bekerja cukup optimal karena cukup menumpuk 50 kertas ke dalam papertray dan menjalankan scanning maka scanner akan memproduksi image secara otomatis satu persatu dengan kecepatan tinggi.
Pada kondisi tertentu pengelompokan image hanya boleh dilakukan sedikit demi sedikit misalkan 10 lembar dan kemudian ditempatkan pada folder tertentu dan kemudian baru boleh memproses batch berikutnya, dalam hal ini scanner tidak akan bekerja optimal karena menunggu interaksi dari operator untuk berpindah-pindah folder. Pada kondisi ini scanner ADF kecepatan 30 ppm maupun 60 ppm tidak banyak berpengaruh pada produktivitas ICR.
Strategi penggunaan batch scanning dengan separator dapat mempercepat kondisi diatas apabila memungkinkan(beberapa aplikasi ICR mendukung batch separator). Batch separator adalah teknik scanning dengan menumpuk antar kelompok dokumen dengan memberikan lembar pemisah atau separator berupa patchcode atau barcode sehingga aplikasi batch scanning membuat folder terpisah secara otomatis setiap kali menemukan separator.
Metode scanning
Kembali pada strategi awal desain
Metode scanning berkaitan dengan strategi awal dalam membuat formulir ICR. Apabila strategi awal menggunakan anchor statis berwarna hitam dengan marking type hitam maka perlu dicari setting scanner yang dapat menghasilkan anchor yang sejelas mungkin dan marking type yang sejelas mungkin. Apabila metode scanning menggunakan color dropout maka perlu diyakinkan bahwa setting scanner mengadopsi color dropout yang sesuai dengan warna formulir ICR dan image yang dihasilkan field yang bersih dari marking type yang tadinya berwarna. Bila metode scanning menggunakan raster maka perlu diaktifkan setting noise removal atau despeckle untuk menghilang titik-titik pada marking type.
Menghilangkan gangguan akibat ukuran kertas yang berbeda-beda
Biasanya beberapa scanner ADF menghasilkan image yang tepinya berwarna hitam apabila ukuran kertas yang didefinisikan pada setting scanner lebih besar dari kertas formulir ICR. Untuk mengatasi hal ini, scanner menyediakan beberapa setting opsi antara lain border removal (menghilangkan bingkai warna hitam yang terjadi pada tepi image), white background (memberikan background putih pada tepi image) , X-Y cropping (memotong gambar dari tepi atas maupun samping) , dan automatic page detection (yaitu otomatis melakukan cropping sesuai ukuran kertas).
Menghilangkan gangguan akibat tipisnya kertas
Kertas tipis seringkali menyebabkan image yang dihasilkan terganggu oleh bayangan lampu scanner, dan muncul sekelompok warna hitam atau abu-abu yang dapat mengganggu pembacaan ICR. Pada scanner tertentu hal ini dapat diatasi dengan mode whitebackground serta penggunaan mode advanced thresholding .
Mengaktifkan Multifeed detection dan waspada terhadap paperjam
Kelemahan scanner ADF pada umumnya adalah menarik kertas lebih dari satu dan juga paperjam atau kertas macet pada scanner. Multifeed detection adalah fitur scanner yang mampu mendeteksi halaman lebih dari satu yang ditarik oleh mekanisme ADF dan secara otomatis menghentikan proses scanning apabila terjadi penarikan ganda.
Pada kondisi paperjam yang perlu diwaspadai adalah penciptaan image berulang pada lembar yang sama oleh aplikasi scanner. Apabila terjadi image berulang , dapat dilakukan penghapusan gambar dan baru mengulang scanning.
Untuk melakukan teknik scanning diatas sangat dibutuhkan pelatihan yang cukup dan pemahaman setting scanner yang benar agar dapat menghasilkan image yang dikehendaki.
Penggunaan Aplikasi ICR
Pada tahap ini aplikasi ICR mulai memproses dan mengenali image hasil dari scanning menjadi teks. Faktor yang mempengaruhi kecepatan operator adalah :
1. Kemampuan operator
2. Kemudahan mengoperasikan ICR
3. Tingkat akurasi recognition dan kecepatan recognition
4. Metode operasi ICR
5. Metode verifikasi
6. Metode validasi
7. Kemudahan mengekspor menjadi hasil yang dikehendaki
1.Kemampuan operator
Kemampuan dan pemahaman operator merupakan kunci sukses dari implementasi ICR. Teknologi ini masih dioperasikan oleh manusia sehingga kelancaran proses dan data yang dihasilkan benar-benar sangat tergantung pada operatornya. Pelatihan yang intensif dan serius serta materi pelatihan yang mengarah pada praktek sangat diharapkan untuk dilakukan pada saat pre-implementasi. Selain itu sikap mental yang mau belajar, teliti serta bertanggungjawab merupakan modal utama menjadi operator ICR yang handal.
2.Kemudahan mengoperasikan ICR
Desain antar muka yang mudah dipahami dan dipelajari menjadi kekuatan aplikasi ICR untuk meningkatkan pemahaman dan berujung pada peningkatan produktivitas dari teknologi ICR. Penting menyembunyikan fitur-fitur dahsyat ICR ke dalam ruang lingkup administrator dan menyerahkan tugas yang mudah ke lingkup operator sehingga kerumitan-kerumitan aplikasi tidak dialami oleh operator.
3.Tingkat akurasi ICR dan kecepatan recognition
Tingkat akurasi dan kecepatan recognition menjadi salah satu faktor penentu kecepatan operasi dengan ICR, dimana akurasi yang baik akan mengurangi jumlah verifikasi yang dilakukan operator (untuk beberapa kasus hal ini benar, pada kasus yang berbeda hal ini menjadi tidak relevan dengan catatan akurasinya masih dicapai angka minimal 70-75%). Kata tingkat akurasi ini menjadi sangat relatif dan tergantung banyak hal terutama faktor yang sebelumnya sudah dibahas yaitu desain awal formulir ICR, kualitas cetak, kualitas scanning serta kualitas tulisan yang mengisi formulir ICR (sudah disosialisasikan cara pengisiannya atau belum) selain metode recognitionnya sendiri.
Apabila diinginkan hasil yang akurat 100% maka semua field yang sudah dikenali oleh ICR harus 100% diverifikasi ulang oleh operator. Proses ini akan memakan waktu cukup lama dan akurasi 80% dengan 90% kemungkinan menjadi kurang relevan untuk menghitung produktivitas ICR pada kondisi ini. Mengapa harus diverifikasi ulang 100% oleh operator dan bukannya yang diragukan saja yang diverifikasi oleh operator ? Dikarenakan tingkat keyakinan baca pada ICR mengandung apa yang dinamakan false positive atau hidden error , sering terjadi ICR yakin dengan yang dibacanya angka “4”, ternyata oleh mata manusia dinyatakan dengan pasti sebagai angka “9”.

Gambar 7. False Positive : dimana yang dimaksudkan adalah KUSUMA namun ICR dengan pasti menebak KUSVMA sehingga tidak muncul di panel verifikasi apabila tidak dilakukan mode full verification.
4.Metode Operasi ICR
Metode operasi ICR biasanya ada dua macam yaitu stand alone dan kolaboratif. Pada sistem stand alone seorang operator melakukan semua proses dari scanning, recognition, verification, validation dan ekspor hasil sehingga semua alur proses akan bergantung pada sebuah komputer dan operatornya. Pada sistem kolaboratif sistem ICR membagi fungsi scanning, recognition, verification , validation dan ekspor pada beberapa operator dan komputer yang berbeda.
Metode standalone dapat digunakan pada suatu sistem yang memperbolehkan data tersebar prosesnya pada beberapa komputer dan hasil yang diharapkan juga terpisah-pisah pada lokasi yang berbeda. Metode ini juga cocok untuk melakukan proses data yang tidak begitu banyak. Kerugian pada sistem ini adalah penggunaan scanner yang tidak efisien, bottleneck pada satu komputer dan konsentrasi operator yang tinggi dalam menangani semua proses.
Metode kolaboratif dapat dipergunakan pada skala besar dan membutuhkan kecepatan proses yang tinggi. Pada proses ini operator scanner hanya melakukan scanning dengan target image yang berkualitas baik untuk dibaca oleh ICR. Verifikator hanya mengecek pembacaan ICR apakah sudah benar. Validator hanya mengecek validasi data yang telah diproses apakah memenuhi syarat atau logika untuk selanjutnya diekspor. Namun pada volume kecil metode ini cenderung merepotkan dan membutuhkan banyak tenaga manusia dan komputer.
5.Metode Verifikasi
Verifikasi adalah proses campur tangan operator “membetulkan” hasil pembacaan ICR yang salah. (inilah alasan mengapa penulis mementingkan sikap mental yang teliti dan bertanggungjawab). Proses ini umumnya diiringi log file yang mencatat pembetulan yang dilakukan oleh operator. Interface verifikasi yang mudah dilakukan dan cepat sangat membantu mempercepat proses ICR.
6.Metode Validasi
7.Kemudahan melakukan ekspor menjadi data yang dikehendaki
Terlintas pengalaman penulis pada suatu implementasi form processing di salah satu lembaga dimana hasil akhir dari ICR dikonversi ke Excel kemudian diatur lagi kolom-kolomnya secara manual untuk kemudian di upload ke web yang menampung hasil pembacaan ICR. Transformasi hasil ekspor inilah yang sering memakan waktu lama dalam memperoleh hasil.
Diperlukan adanya presetting pada fungsi ekspor sehingga aplikasi ICR dapat langsung menghasilkan data yang dikehendaki atau paling tidak siap diekspor atau diimpor ke aplikasi lainnya untuk pengolahan lebih lanjut.
Adanya support on-time yang memadai dan mekanisme support yang mudah dilakukan
Pada awal implementasi operator sering mengalami demam panggung atau biasanya malah tidak pernah melakukan gladi resik atau pelatihan sebelum mengoperasikan teknologi ICR. Beberapa problem yang muncul adalah instalasi aplikasi dan scanner, belum mengetahui setting scanner, problem dengan hasil cetak formulir ICR, belum mengetahui penggunaan ICR, serta kesulitan menghadapi validasi dan ekspor.
Untuk menangani hal ini diperlukan sistem support yang memadai dan mudah, misalnya dengan secara sederhana mengirimkan hasil scanning pada support untuk kemudian ditindaklanjuti dengan membalas email solusinya atau desain template yang cocok untuk menghadapi situasi yang dihadapi. Kelambatan dan ketiadaan support menimbulkan kelambatan proses ICR yang tidak terukur.
Perhitungan Risiko pada Teknologi ICR dan Pengaruhnya Pada Keberhasilan dan waktu Prosesnya.

Dengan beberapa faktor diatas maka penulis mencoba melakukan tabulasi risiko dan pengaruhnya terhadap produktivitas sistem ICR
Demikian sekiranya beberapa faktor utama yang menurut penulis mempengaruhi waktu proses dari suatu teknologi ICR, sebatas pengetahuan penulis. Faktor – faktor ini kiranya dapat diperhitungkan dalam melakukan estimasi proses ICR dan dapat dipertimbangkan sebagai suatu tahapan kritikal yang harus dipertimbangkan dalam implementasi penggunaan ICR pada suatu proses data entry. Tentunya banyak hal-hal lain yang dapat mempengaruhi waktu proses maupun tingkat keberhasilan dalam implementasi yang luput dari perhatian penulis yang diharapkan dapat menjadi masukan untuk menyempurnakan pengetahuan penulis yang terbatas berdasarkan pengalaman di beberapa proyek di Indonesia.
Langganan:
Postingan (Atom)